
Продолжаю свою серию заметок про трюки ggplot2, предыдущие заметки серии:
Краткое вступление 🤏
Одной из трудных для освоения областей при работе с визуализацией – является отображение различных агрегированных статистик вроде суммы, среднего, медианы и тому подобного. Действительно, часто хочется одновременно лицезреть и структуру и обобщающую совокупность на одном графике. Данная заметка будет посвящена тому как получить желаемый результат без особых напряжений.
library(thematic) # пакет для автоматической установки стилей графиков
library(tidyverse) # набор пакетов по принципу "все включено", в который включен ggplot2
library(ggpp) # расширение для ggplot2
library(DT) # пакет создания интерактивных таблиц
# Активируем тему для блога
thematic_rmd(bg = "#1D1E20", accent = "cyan", fg = "grey90",
font = font_spec("Roboto"), sequential = firatheme::firaPalette(100),
qualitative = palette.colors(palette = "Tableau"))
# Сохраняем палитру в отдельную переменную
my_pal <- palette.colors(palette = "Tableau") %>% unname()
Цены на жилье 🏘
Вероятно, по моим предыдущим заметкам было понятно, что я стараюсь выбирать интересные с экономической точки зрения сведения для демонстрации возможностей ggplot2. Продолжая данную традицию, в этот раз были выбраны статистические сведения по динамике цен 1 кв. метра общей площади квартир, любезно предоставленные РОССТАТОМ.
Многие, кто сталкивался с системой публикации статистических данных ЕМИСС, испытали болезненный жизненный опыт в попытках выгрузить сведения, пригодные для анализа. ЕМИСС требует немалой усидчивости от пользователя для “натыкивания” нужных аналитических разрезов т.к. при добавлении каждого измерения делается запрос в базу данных, который вытаскивает несколько сотен мегабайт информации на интерфейс. Естественно, такая шарманка часто ломается, подвисает и вынуждает пользователя начинать “натыкивание” с самого начала, что вызывает целый букет ярких впечатлений 🤕
К счастью, я нашел отличный лайфхак как избежать описанных выше мучений. Добрый люди написали пакет для R, который существенно уменьшает размер боли от взаимодействия с ЕМИСC. Пользуясь случаем, предлагаю пройти по ссылке и поставить звездочку для того чтобы усилить мотивацию авторов развивать проект 🌟
Пара десятков строчек кода и 5-10 секунд ожидания позволяют сформировать приличный датасет на ~70 тыс. наблюдений. Код с выгрузкой данных из ЕМИСC и дальнейшей подготовкой данных останется за рамками данной заметки. Пример полученных сведений по по динамике цен 1 кв. метра общей площади квартир:
house <- fst::read_fst("data/house.fst")
slice_sample(house, n = 30) %>% # 30 случайных наблюдений
datatable(style = 'bootstrap4', extensions = 'Responsive',
options = list(pageLength = 10),
caption = "Котировки технологических гигантов")
Очевидное решение 👀
Первым делом при знакомстве с новым датасетом хорошо бы составить впечатление о полноте самих данных, собираемых Росстатом. Далее будет рассматриваться динамика изменения цены и следовательно любопытно посмотреть насколько регулярно готовилась соответствующая статистика. Визуализация агрегированного количества наблюдений/строчек в разрезе типов квартир и рынков – будет неплохой идеей. Для того чтобы получить количество наблюдений будет использована популярная комбинация dplyr::group_by и далее dplyr::summarise:
house %>%
group_by(date, s_vidryn, S_TIPKVARTIR) %>% # группировка по дате, виду рынка, типу квартиры
summarise(n = n()) %>% # агрегация по созданной группировке
ggplot(aes(date)) +
annotate("text_npc", npcx = .5, npcy = .5, alpha = .9, size = 15,
label = "InvestCookies.ru", color = "#1D1E20") +
geom_col(aes(y = n, fill = S_TIPKVARTIR), alpha = .6) +
facet_wrap(~s_vidryn, nrow = 2) +
scale_x_date(date_breaks = "year", date_labels = "%Y") +
guides(fill = guide_legend(nrow = 2)) +
labs(title = "Количество наблюдений за период по видам отчетности",
fill = "Тип квартиры", x = "Квартал", y = "Количество отчетов") +
theme(legend.position = "bottom", axis.text.x = element_text(angle = 45))
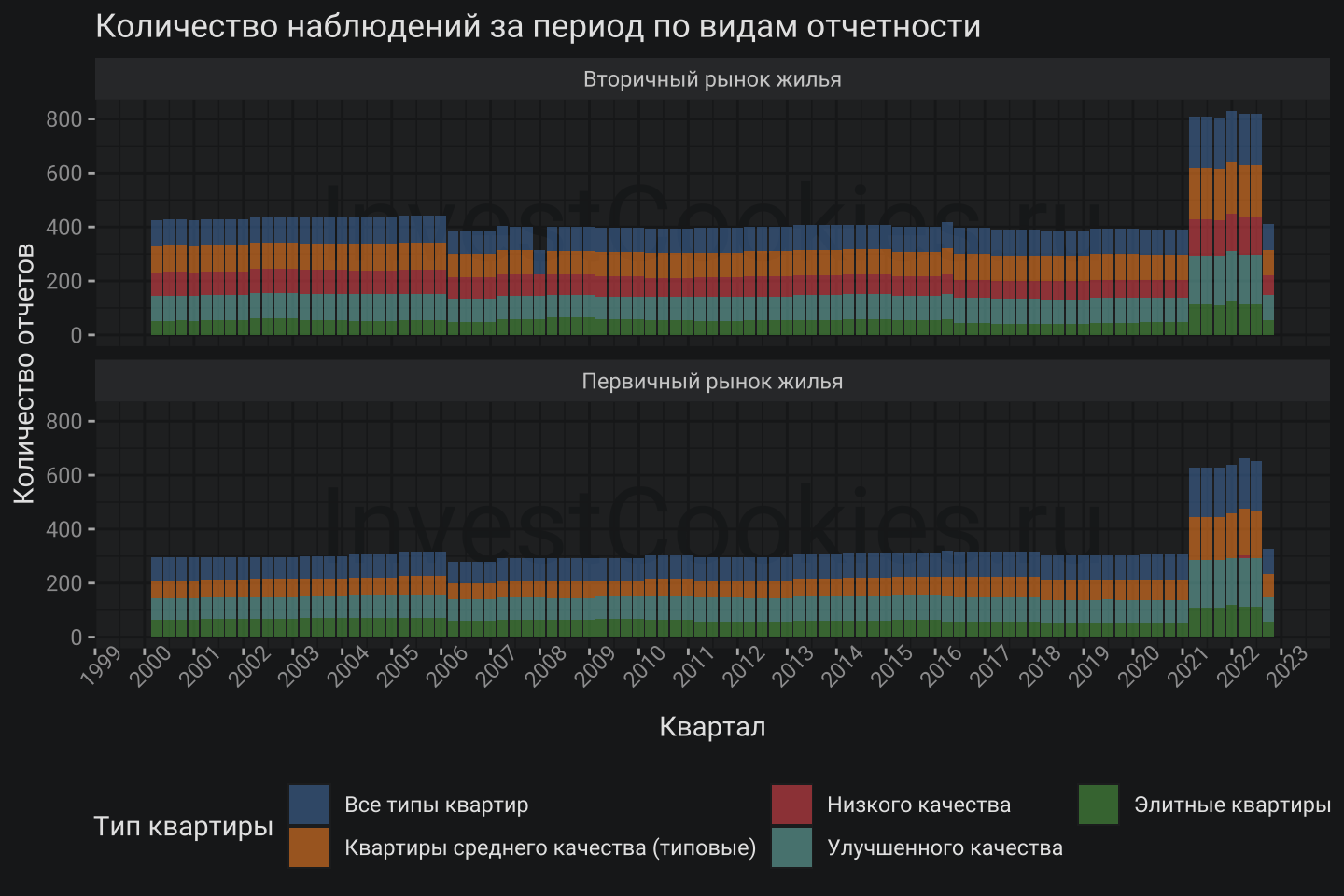
Получается столбчатый график, который демонстрирует некоторую нерегулярность статистических сведений во времени. Если копнуть глубже в данные то можно заметить, что с 2021 года Росстат начал вести статистику в разрезе 1) столицы региона и 2) прочей его части. Также можно заметить, что Первичный рынок жилья не включает категорию Низкого качества.
В целом данный подход дает результат, но если нужно будет добавить на график сумму количества наблюдений то придется подготовить отдельный датасет с соответствующей агрегацией, которая не будет включать группировку по типу квартир S_TIPKVARTIR и далее использовать его для построения графика. Ситуация усугубляется, когда таких агрегаций нужно сделать несколько. К счастью, ggplot2 предлагает решение такой проблемы.
Делай stat 1 🤹
Вместо конструкции dplyr::group_by и далее dplyr::summarise можно использовать параметр stat внутри geom_bar и geom_text. Первый нарисует колоночки аналогично geom_col, но сразу просуммирует количество наблюдений благодаря конструкции after_stat(count) внутри aes(), второй нарисует суммарное значение в виде текста:
house %>%
ggplot(aes(date)) +
annotate("text_npc", npcx = .5, npcy = .5, alpha = .9, size = 15,
label = "InvestCookies.ru", color = "#1D1E20") +
geom_bar(aes(y = after_stat(count), fill = S_TIPKVARTIR), stat = "count", alpha = .6) +
geom_text(aes(label = after_stat(count), y = after_stat(count)), stat = "count",
alpha = .6, check_overlap = TRUE, size = 2, angle = 45) +
facet_wrap(~s_vidryn, nrow = 2) +
scale_x_date(date_breaks = "year", date_labels = "%Y") +
guides(fill = guide_legend(nrow = 2)) +
labs(title = "Количество наблюдений за период по видам отчетности",
fill = "Тип квартиры", x = "Квартал", y = "Количество отчетов") +
theme(legend.position = "bottom", axis.text.x = element_text(angle = 45))
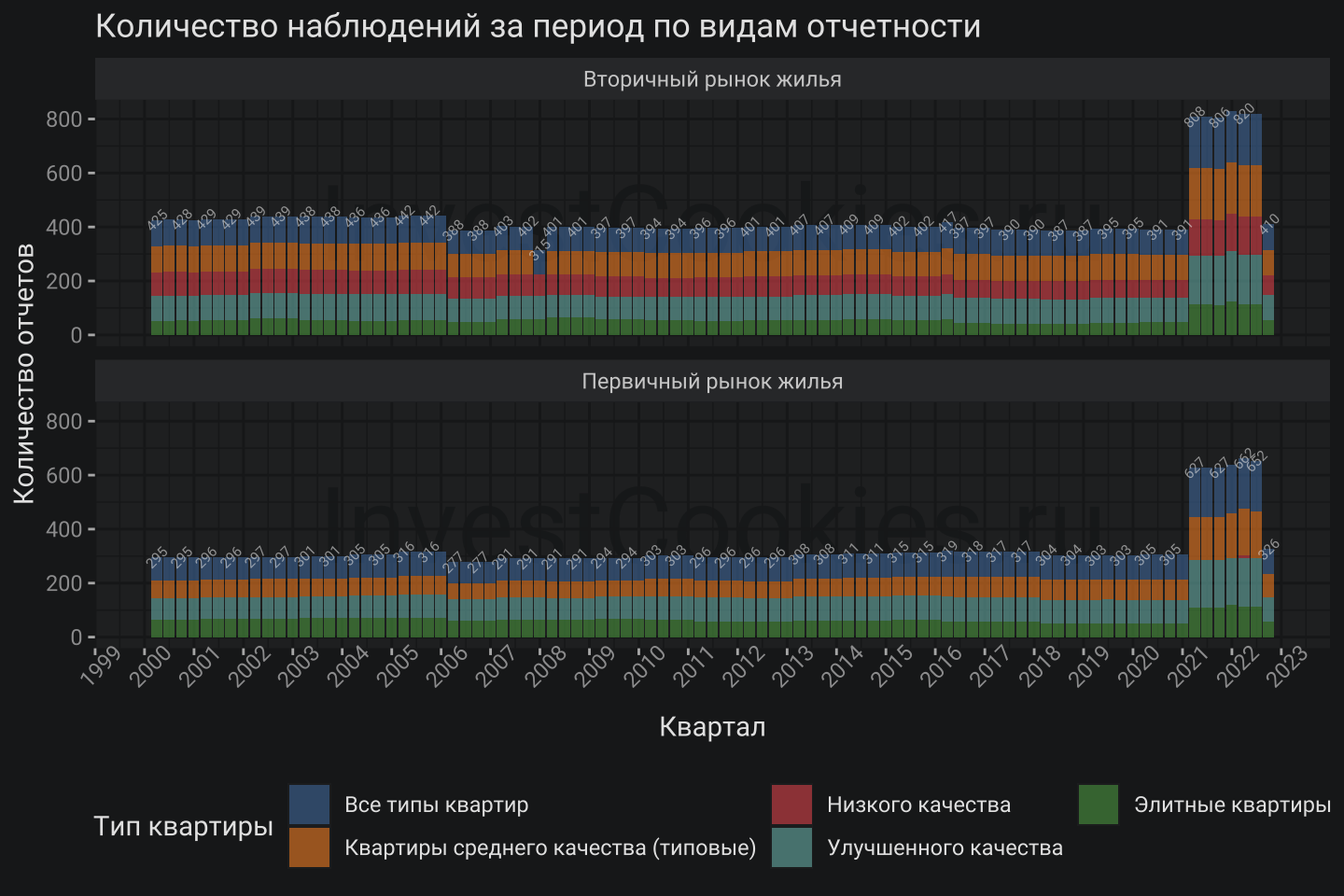 Для того чтобы
Для того чтобы geom_text показывал суммы наблюдений по всем типам квартир было достаточно просто убрать из aes() параметр color = S_TIPKVARTIR т.е. параметр раскраски по цветам. Если же его оставить то выводится сумма по каждому цвету.
Очевидно, что данный вариант гораздо более гибкий и компактный в сравнении с первым подходом 😎
Делай stat 2 🤹🤹
После проверки целостности датасета можно приступить непосредственно к анализу цен для чего будут выбраны три фокусных региона: Москва, Санкт-Петербург и Краснодарский край:
house %>%
filter(s_OKATO_code %in% c("45000000000", "40000000000", "03000000000")) %>%
ggplot(aes(date)) +
annotate("text_npc", npcx = .5, npcy = .5, alpha = .9, size = 15,
label = "InvestCookies.ru", color = "#1D1E20") +
geom_line(aes(y = ObsValue, color = S_TIPKVARTIR, linetype = s_vidryn)) +
facet_wrap(~s_OKATO, nrow = 3, scales = "free") +
scale_y_continuous(labels = scales::label_comma(suffix = " тыс. руб.", scale = .001)) +
scale_x_date(date_breaks = "year", date_labels = "%Y") +
labs(title = "Динамика цен 1 кв. метра общей площади квартир",
color = "Тип квартиры", x = "Квартал", y = "Цена квадратного метра",
linetype = "Тип рынка") +
guides(color = guide_legend(nrow = 3, title.position = "top"),
linetype = guide_legend(nrow = 2, title.position = "top")) +
theme(legend.position = "bottom", axis.text.x = element_text(angle = 45))
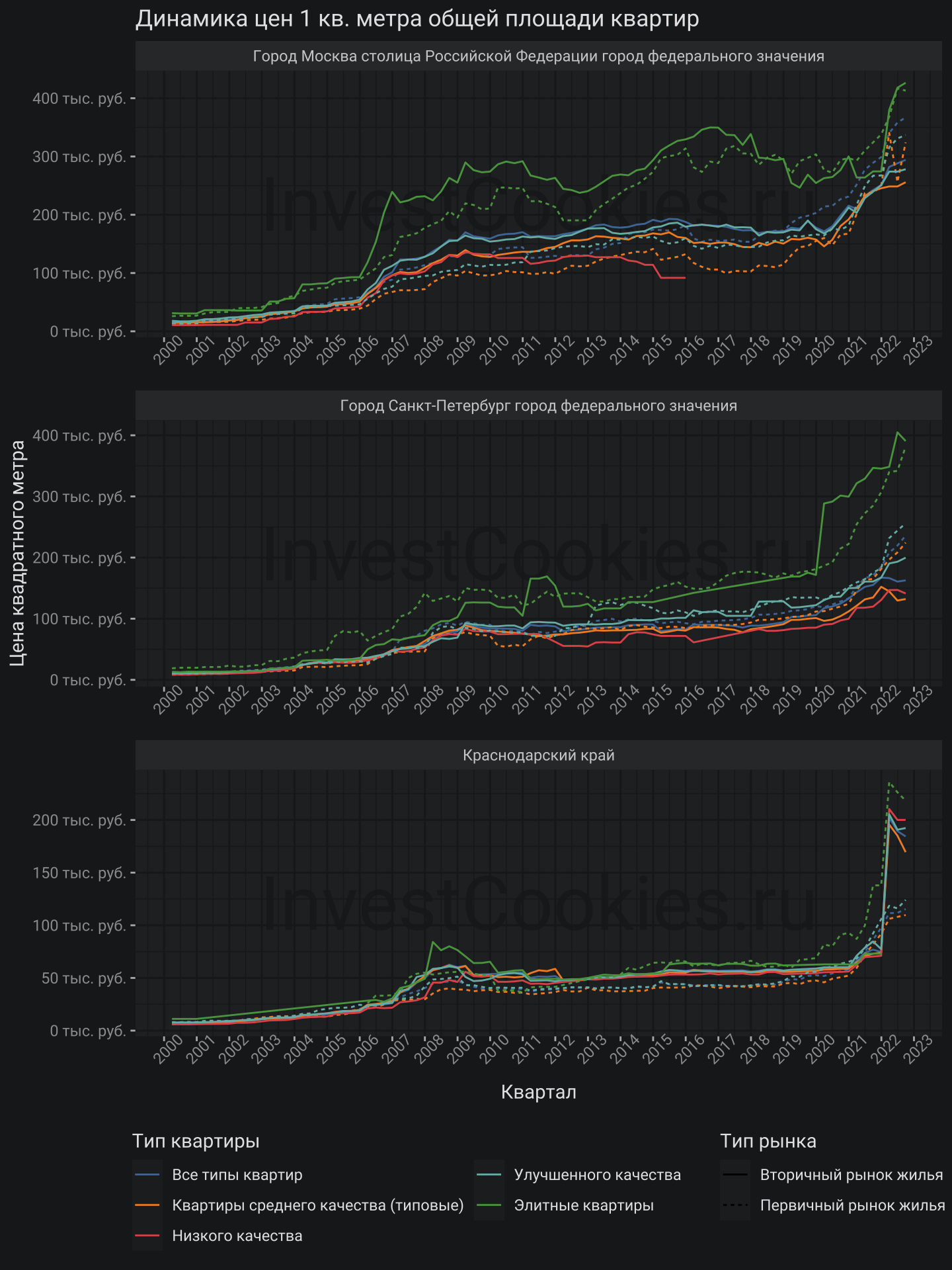
Получились графики для трех регионов, пяти типов квартир и двух рынков. Графики можно анализировать в таком виде, но было бы неплохо агрегировать значения в средние и медианные. Для данной задачи будет использованы специальные геометрии stat_summary, которые способны агрегировать информацию прямо внутри себя для чего необходимо задать функцию агрегации fun и тип визуализации geom:
house |>
filter(s_OKATO_code %in% c("45000000000", "40000000000", "03000000000")) |> # фильтрация фокусных регионов
ggplot(aes(date)) +
annotate("text_npc", npcx = .5, npcy = .5, alpha = .9, size = 15,
label = "InvestCookies.ru", color = "#1D1E20") +
stat_summary(aes(y = ObsValue, label = ObsValue), geom = "text", check_overlap = TRUE, alpha = .4, size = 3,
fun.data = \(x)tibble(y = 0, label = round(median(x)/1e3, 1)), angle = 90, hjust = 0) +
stat_summary(aes(y = ObsValue), geom = "col", check_overlap = TRUE, alpha = .2,
fun.data = \(x)tibble(y = median(x), label = round(median(x)/1e3, 1))) +
stat_summary(aes(y = ObsValue, linetype = s_vidryn, col = "Среднее"), geom = "line", fun = "mean") +
stat_summary(aes(y = ObsValue, linetype = s_vidryn, col = "Медиана"), geom = "line", fun = "median") +
facet_wrap(~s_OKATO, nrow = 3, scales = "free") +
scale_y_continuous(labels = scales::label_comma(suffix = " тыс. руб.", scale = .001)) +
scale_x_date(date_breaks = "year", date_labels = "%Y") +
scale_color_manual(values = c("Среднее" = my_pal[1], "Медиана" = my_pal[2])) +
labs(title = "Динамика цен 1 кв. метра общей площади квартир",
color = "Тип агрегации", x = "Квартал", y = "Цена квадратного метра",
linetype = "Тип рынка", caption = "Текстом и столбцами показаны медианные значения цен по всем типам квартир и рынкам") +
guides(color = guide_legend(nrow = 2), linetype = guide_legend(nrow = 2)) +
theme(legend.position = "bottom", axis.text.x = element_text(angle = 45))
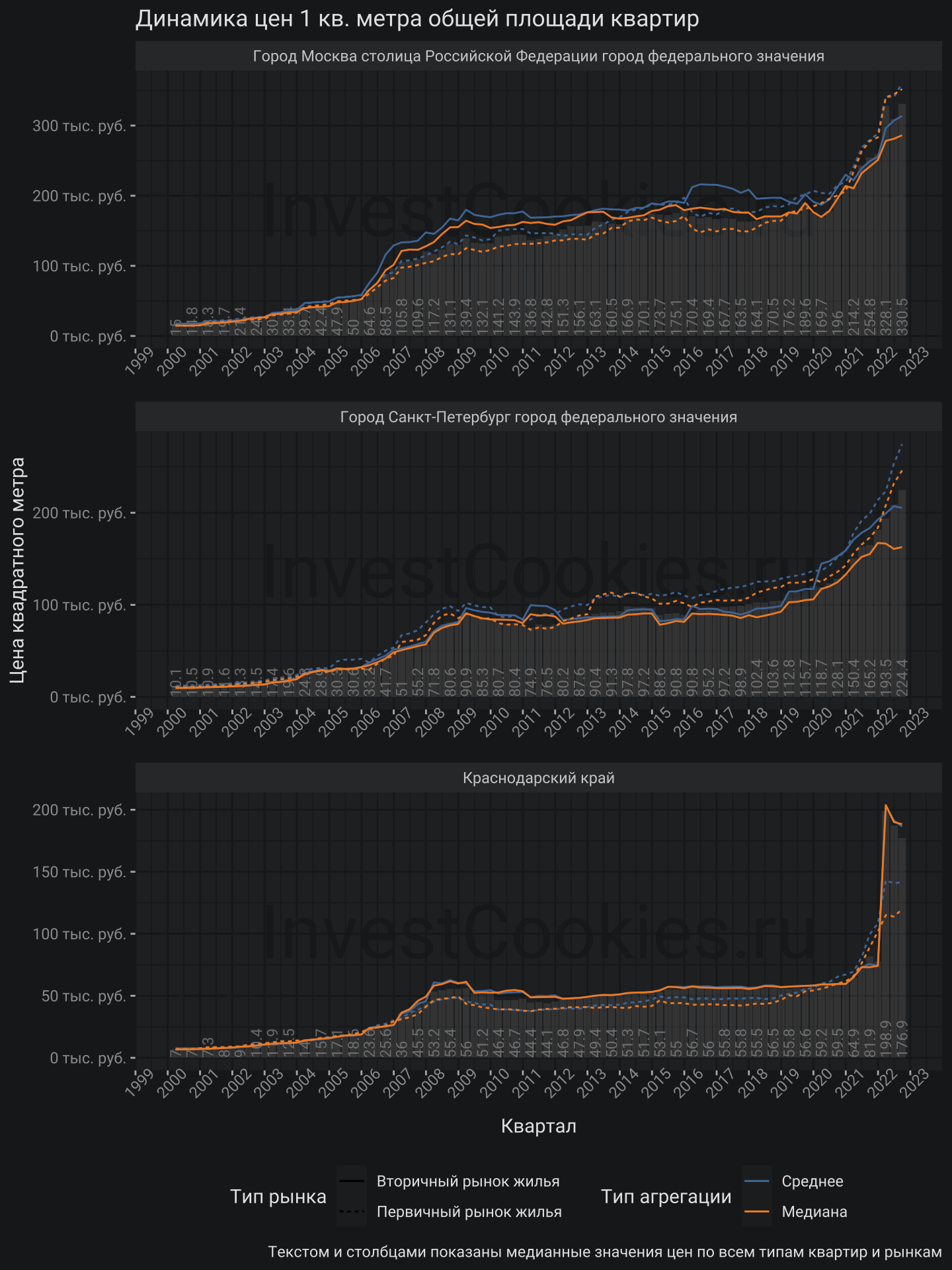
В данном случае для того чтобы нарисовать медианные значения в виде текста пришлось прибегнуть к параметру fun.data, который позволяет налету генерировать данные нужного уровня агрегации. Цвета медианы и среднего заведены в aes статическим образом (текстовым значением), что подробно разбиралось тут.
Можно заметить, средние цены почти всегда выше медианных, что связано с более агрессивным ростом элитного сегмента по всем регионам. Другими словами, рост цен массового рынка менее выражен чем средний рост цен. Для полноты картины приведу наглядное пояснение различия значений среднего и медианного:

Итоги 🍪
Несмотря на то, что заметка носит технический характер сложно удержаться от комментариев по рынку жилой недвижимости, которая многих волновала, волнует и будет волновать:
- Краснодарский край за счет Сочи и не только ракетой стремиться к ценам Питера и Москвы буквально за пару кварталов 2022 года 🚀
- Элитная недвижимость выросла гораздо более выражено чем прочие виды. Очевидно, состоятельные граждане активно парковали средства в недвижимости сначала на фоне разгона инфляции 2021, а потом на фоне эскалации вооруженного конфликта 2022 года. Теперь рынок элитного жилья либо существенно будет скорректирован т.к. он не способен генерировать лишь сколько бы значимый возврат на капитал, либо вырастет еще сильнее в случае бегства капитала из иностранных юрисдикций и последующей парковке в чем то реальном. Поэтому в данном случае что-то предсказать кроме высокой волатильности будет достаточно сложно 🎢
- Цены на первичное жилье за последний год сделали сильный рывок и сейчас существенно превышают цены на вторичном рынке. Конечно, такая инверсия не может продолжаться вечно и вторичный рынок будет торговаться дороже первичного, а пока акции строительных компаний выглядят весьма перспективно: именно они являются главными бенефициарами, сложившейся ситуации 🏗
- Массовый рынок жилья скорей всего ждет некоторая коррекция в силу падения платежеспособного спроса в силу падения доходов населения от всего всего, что происходит ⏬
Простой способ узнать о новых публикациях – подписаться на Telegram-канал: