StoryTelling 🕵🏿
Цифры имеют поразительную силу влияния на людей: одним своим существованием они заявляют о наличие объективного факта, который мало кто готов оспорить. К сожалению, цифры также имею свою слабость: их бывает сложно интерпретировать. Например, все знают, что такое инфляция, но мало кто знает как инфляция рассчитывается и также мало кто знает, что инфляция бывает разная. В итоге в головах обывателей формируется мутное ощущение того, что инфляция не отражает динамики цен на их любимый двойной карамельный макиато в старбаксе ☕
Решение боевых задач бизнеса или сферы инвестирования требует более глубокого погружения в суть вещей с целью поиска потенциалов приложения усилий и извлечения прибыли. Эффективный анализ не может существовать без данных и также не может существовать без понятного графического представления этих данных. Графики должны интерпретировать данные и подводить к тайнам, которые скрыты за безжизненными и сухими цифрами. В этом отношении визуализация данных – это искусство, которым должны в совершенстве владеть аналитики и дата-сайентисты, если они хотят чтобы их проекты были успешны. Графики должны иметь сюжет и рассказывать историю о том, что они содержат. Именно это свойство легло в основу нового тренда рынка BI-инструментов согласно отчетам Gartner. Такой тренд был назван StoryTelling. Вот что они пишут на своем сайте:
When it comes to telling your most impactful story, you are not fully utilizing your best asset – your data. Data storytelling is an extension of the now-dominant self-service model of business intelligence (BI), combining data visualization with narrative techniques.
или в моем вольном переводе:
Тот момент когда тебе нужно донести наиболее значимую историю, но ты не используешь свой лучший аргумент – твои данных. StoryTelling – это расшиерение доминирующей сегодня концепции самообслуживания в BI, которое сочетает визуализацию данных и технику повестования.
Осталось только дополнить эту мысль тем, что создание повествующей визуализации возможно только с помощью пригодного для этого инструмента и именно о таком инструменте далее пойдет речь. Пакет визуализации ggplot2 на языке R практически безупречен в своей способности визуализировать и доносить идеи, скрытые в данных. Я оцениваю совершенство инструмента по нескольким критериям:
- Стоимость входа т.е. количество времени, которое нужно потратить на освоение инструмента – в этом отношении
ggplot2без остатка уступает всем BI инструментам, но уверенно обходит любые аналоги, основанные на программировании, включая Pythonmatplotlib - Функциональные возможности т.е. способность покрывать все возможные и не возможные пожелания того как изображаются данные через удобный и интуитивно понятный интерфейс управления настройками. Последний пункт крайне важен т.к. увеличение объема функциональности обратно пропорционально удобству обращения с этим инструментом и тут у
ggplot2просто нет равных. Сложно сказать какие инструменты способны конкурировать по этому критерию сggplot2. На ум приходят преимущественно пакеты из javascriptD3.js,Echarts, но интерфейс управления визуализацией там весьма замысловатый - Комьюнити – это не только возможность найти ответы на любые вопросы через поисковую строку, но это еще и тысячи людей, которые создают функциональные дополнения, расширяя сценарии использования
ggplot2. При этом такие расширения используют единую синтаксическую основу т.е. единожды освоив концепцию построения графика вggplot2аналитик получает вагон и маленькую тележку всяких разных полезностей: визуализация графов, создание анимированной и интерактивной визуализации, создание графиков для предметных областей типа генных исследований или настольных игр. Некоторые, наиболее популярные, расширения можно найти на ggplot2 extensions
Другими словами, даже если вы пишите больше на Python или другом языке, или вы в совершенстве владеете Excel c PowerBI, но хотите чтобы визуализация данных была предельно убедительной, то вопрос об изучении ggplot2 теряет свою актуальность, но скорее возникают вопросы когда и как его изучать 🙃
Существуют много прекрасных книг, которые основные принципы работы с ggplot2, включая даже книгу BBC о том как следует использовать ggplot2 для журналистики 📰
Собственно я не считаю нужным повторять то, что изложено в книгах и учебниках, но я хотел бы собрать серию заметок, которая раскрывает некоторые аспекты создания визуализации с помощью ggplot2. В основном я буду разбирать частые вопросы, которые возникают у новых пользователей, но ответы на которые могут быть найдены только на StackOverflow или на подобных тому ресурсах. Буду стараться по шагам пояснять, что и зачем происходит, иногда немного отходя от основной линии.
Первая область, которую я хотел бы разобрать – это легенда – такая штука, которая поясняет какой график чему соответствует. В силу того, что фокус моих интересов пролегает в области финансового анализа в качестве рабочих данных буду использовать достаточно заурядные котировки четырех технологических гигантов:
- Apple
- Microsoft
- 🚙 Tesla
Подготовка 🏁
В первую очередь подготовим рабочее окружение, которое необходимо для визуализации:
library(thematic) # пакет для автоматической установки стилей графиков
library(quantmod) # пакет для загрузки информации о биржевых котировках
library(tidyverse) # набор пакетов по принципу "все включено", в который включен ggplot2
library(memoise) # пакет кеширования результатов вывода функции
library(ggpp) # расширение для ggplot2
library(DT) # пакет создания интерактивных таблиц
# Активируем тему для блога
thematic_rmd(bg = "#1D1E20", accent = "cyan", fg = "grey90",
font = font_spec("Roboto"), sequential = firatheme::firaPalette(100),
qualitative = palette.colors(palette = "Tableau"))
# Сохраняем палитру в отдельную переменную
my_pal <- palette.colors(palette = "Tableau") %>% unname()
Как можно заметить из сниппета кода выше, я настроен использовать палитру Tableau потому что сочные цвета данной палитры хорошо смотрятся на темном фоне, который я использую в качестве визитной карточки для своеобразного брендирования моего проекта. Люблю изыскано-подобранные сочные цвета с тонким французским вкусом.
Использование палитры из переменной – это достаточно простая, но крайне полезная привычка при работе с графиками, которая позволяет легко брендировать графики в случае необходимости. Такой необходимостью, например, может быть требование вашего заказчика использовать корпоративные цвета из брендбука или просто неуемная тяга к прекрасному 👨🏾🎨
Следующим шагом будут загружены данные и произведена небольшая подготовка для чего я буду использовать самописную функцию get_symbols(). Смысл этой функции заключается в том, чтобы на вход подать перечень тикеров котировок, а на выходе иметь табличку правильного формата. Далее get_symbols() оборачивается в функцию memoize() для того чтобы при новых вызовах функции с прежними параметрами результат вывода брался из кеша, а не дергал каждый раз API провайдера данных, что очевидно ускоряет процесс исполнения скрипта и существенно снижает риск быть забаненым у провайдера данных:
# Функция загрузки котировок
get_symbols <- function(sym_vec){
# Общие имена колонок, которые будут использованы для всех тикеров
nms <- c("Time", "Open", "High", "Low", "Close", "Volume", "Adjusted")
map(sym_vec, ~getSymbols(., auto.assign = FALSE) %>%
as_tibble(rownames ="Time") %>% set_names(nms)) %>%
set_names(sym_vec) %>%
bind_rows(.id = "Ticker") %>%
mutate(Time = as.Date(Time))
}
# Команда кеширования результатов вывода функции
get_symbols_cache <- memoize(get_symbols)
Далее формируется список тикеров компаний и список красивых названий, который будет использован для визуализации. Список красивых имен tick_names формируется в виде именованного вектора, что делает возможным удобный переход от тикеров к именам.
ticks <- c("MSFT", "GOOG", "AAPL", "TSLA")
tick_names <- c("MICROSOFT", "GOOGLE", "APPLE", "TESLA") %>% set_names(ticks)
# Записываем котировки
tickers0 <- get_symbols_cache(ticks)
# Переменная для условного форматирования таблицы
brks <- quantile(tickers0[, 3:6], probs = seq(.05, .95, .05), na.rm = TRUE)
# Табличка с рюшечками и кружавчиками
slice_sample(tickers0, n = 100) %>% # 100 случайных наблюдений
datatable(style = 'bootstrap4', extensions = 'Responsive',
options = list(pageLength = 10),
caption = "Котировки технологических гигантов") %>%
formatRound(c(3:6, 8), digits = 2, mark = " ") %>%
formatStyle(3:6, backgroundColor = styleInterval(brks, firatheme::firaPalette(length(brks) + 1)))
Далее динамика котировок будет нормирована на шкалу от 0 до 1 для наглядного сравнения движения цен или объемов. Это не вполне стандартный прием так как все привыкли видеть цены акций на биржевых сводках, но в действительности, относительных цен вполне достаточно для того чтобы оценить прибыль или убытки.
Для трансляции значений в шакалу от 0 до 1 используется удобная функция scales::rescale():
# Нормирование на шкалу от 0 до 1
tickers1 <- tickers0 %>%
group_by(Ticker) %>%
mutate(across(-Time, ~scales::rescale(., to = c(0, 1))))
# Переменная для условного форматирования новой таблицы
brks <- quantile(tickers1[, 3:6], probs = seq(.05, .95, .05), na.rm = TRUE)
# Табличка с рюшечками и кружавчиками
slice_sample(tickers1, n = 100) %>% # 100 случайных наблюдений
datatable(style = 'bootstrap4', extensions = 'Responsive', options = list(pageLength = 10),
caption = "Котировки технологических гигантов в относительных значениях") %>%
formatRound(c(3:8), digits = 2, mark = " ") %>%
formatStyle(3:8, backgroundColor = styleInterval(brks, firatheme::firaPalette(length(brks) + 1)))
Паттерн 🌝
Когда разговор доходит за инструмент, то всегда существует правильное применение инструмента и не очень, что собственно программисты называют модным словом антипаттерн. Например, заколачивание телескопом гвоздей – это возможный способ применения телескопа, но не самый лучший. Соответственно, если кто-то будет использовать R, но писать код также как это делалось на Python – это тоже будет антипаттерн. Иными словами тот кто всю жизнь забивал гвозди, получив телескоп – будет продолжать забивать гвозди, что бы он не получил в руки. Это не плохо и не хорошо, но для конечного успеха требуется понимание, что является хорошим подходом, а что является плохим. Далее я покажу как работает паттерн с ggplot2 и как работает антипаттерн.
Обратите внимание как были подготовлены данные: тикеры компании собраны в одну колонку вместо того чтобы иметь много колонок т.е. более широкую табличку. Данные, подготовленные таким образом в отношении тикеров – являются паттерном для ggplot2 т.е. правильным подходом. Предлагаю посмотреть насколько сложно построить график для таких данных:
ggplot(tickers1, aes(Time, Close, col = Ticker)) + # формирование оснастки графика
annotate("text_npc", npcx = .5, npcy = .5, alpha = .9, size = 15, # для брендирования
label = "InvestCookies.ru", color = "#1D1E20") + # для брендирования
geom_line() # непосредственно график кривой
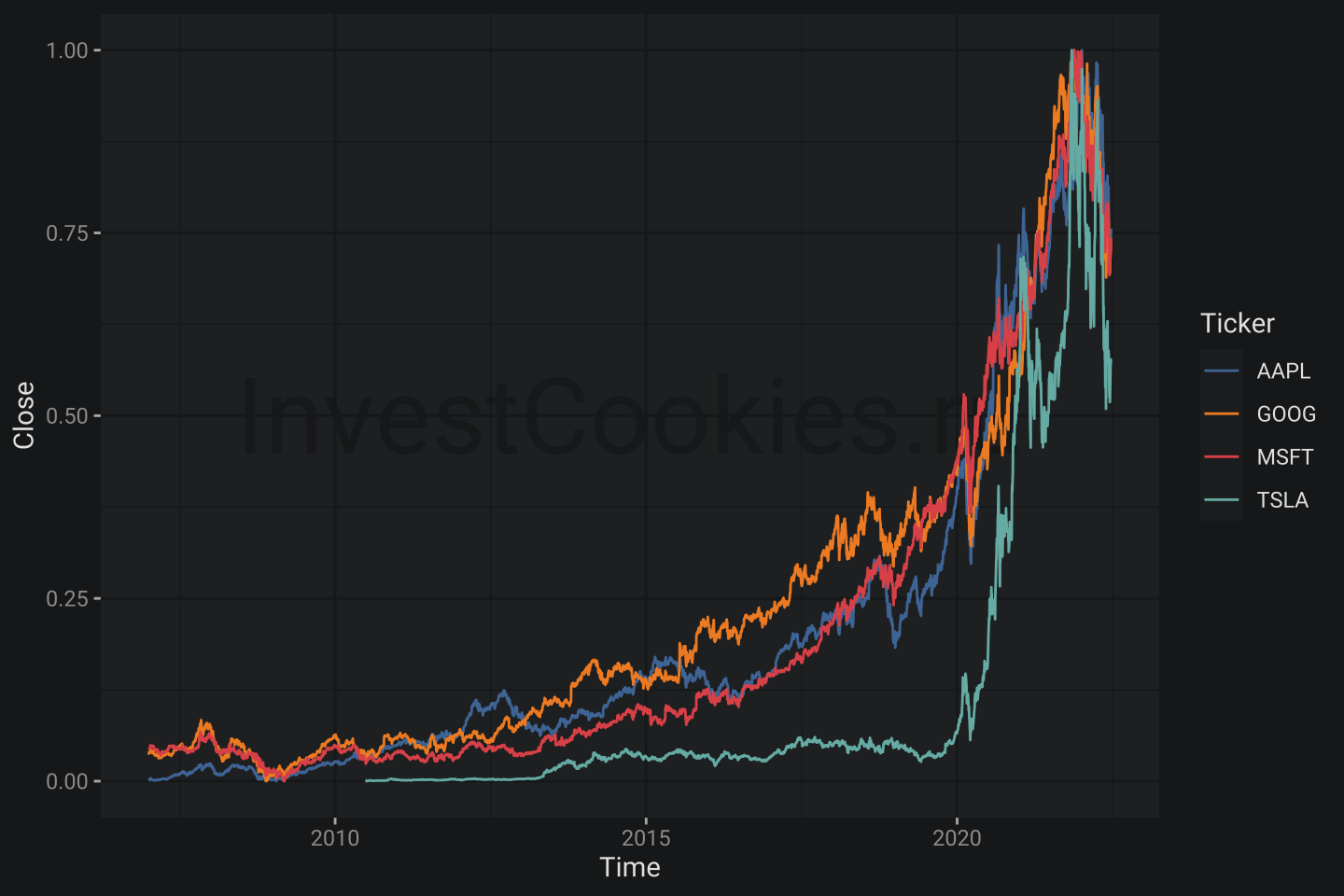 В целом график получился вполне нормальный с учетом того, что мы написали всего две строчки кода (без учета строчки брендирования). На этом можно было бы даже успокоиться, но давайте представим, что мы работаем на компанию Microsoft и менеджмент этой компании категорически не приемлет указания Microsoft следом за компанией Google. Капризы, скажете вы и возможно будете правы, но в контексте бизнеса такие вещи могут быть принципиальными. Нужно ли говорить, что очередность вывода в легенде – это непростая задача для других пакетов? Вот тут можно посмотреть решение для
В целом график получился вполне нормальный с учетом того, что мы написали всего две строчки кода (без учета строчки брендирования). На этом можно было бы даже успокоиться, но давайте представим, что мы работаем на компанию Microsoft и менеджмент этой компании категорически не приемлет указания Microsoft следом за компанией Google. Капризы, скажете вы и возможно будете правы, но в контексте бизнеса такие вещи могут быть принципиальными. Нужно ли говорить, что очередность вывода в легенде – это непростая задача для других пакетов? Вот тут можно посмотреть решение для matplotlib, которое требует написание двух циклов. Неплохая разминка для ума, но я бы предпочел сохранить в голове побольше серого вещества для более приятных вещей 🤯
Теперь то, что нужно сделать в ggplot2 – это просто добавить scale_color_discrete():
ggplot(tickers1, aes(Time, Close, col = Ticker)) +
geom_line() +
scale_color_discrete(breaks = ticks, # устанавливают очередность
labels = tick_names) # изменяют ярлыки
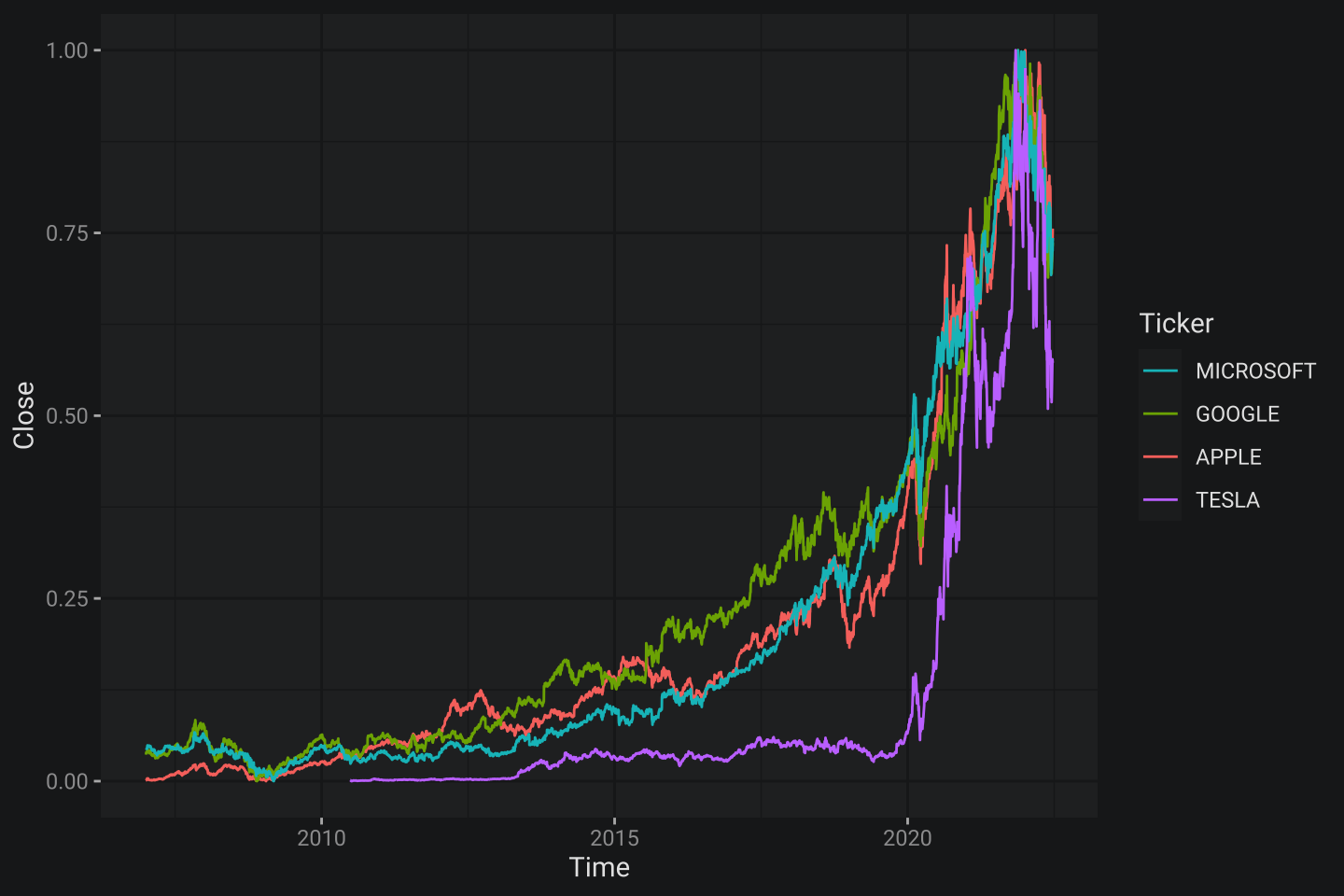 Вот собственно и все: лаконично и логично без циклов и предварительного выдирания легенды парой методов. Это наглядная демонстрация того как правильный интерфейс справляется с многообразием доступной функциональности. Таких примеров существует множество, но эта заметка не создана для того чтобы я катался катком по
Вот собственно и все: лаконично и логично без циклов и предварительного выдирания легенды парой методов. Это наглядная демонстрация того как правильный интерфейс справляется с многообразием доступной функциональности. Таких примеров существует множество, но эта заметка не создана для того чтобы я катался катком по matplotlib или другим инструментам визуализации 🚜
Теперь я хотел бы поменять цвета графика на те, которые содержатся в брендбуке, что будет сделано с помощью функции более тонкой настройки scale_color_manual() с помощью аргумента values. Для пущей наглядности добавлю сглаженную версию графиков:
# Создаем вектор произвольных цветов и даем имена цветам
# Каждому цвету будет соответствовать свой тикер, поэтому каждому тикеру можно задать определенный цвет
cols1 <- c("steelblue", "darkcyan", "coral", "firebrick") %>% set_names(ticks)
ggplot(tickers1, aes(Time, Close, col = Ticker)) +
annotate("text_npc", npcx = .5, npcy = .5, alpha = .9, size = 15,
label = "InvestCookies.ru", color = "#1D1E20") + # для брендирования
geom_line(alpha = .2) +
scale_color_manual(values = cols1) + # меняет цвета на брендированные
stat_smooth(span = .1, method = 'loess', formula = 'y ~ x') # сглаженная версию графиков
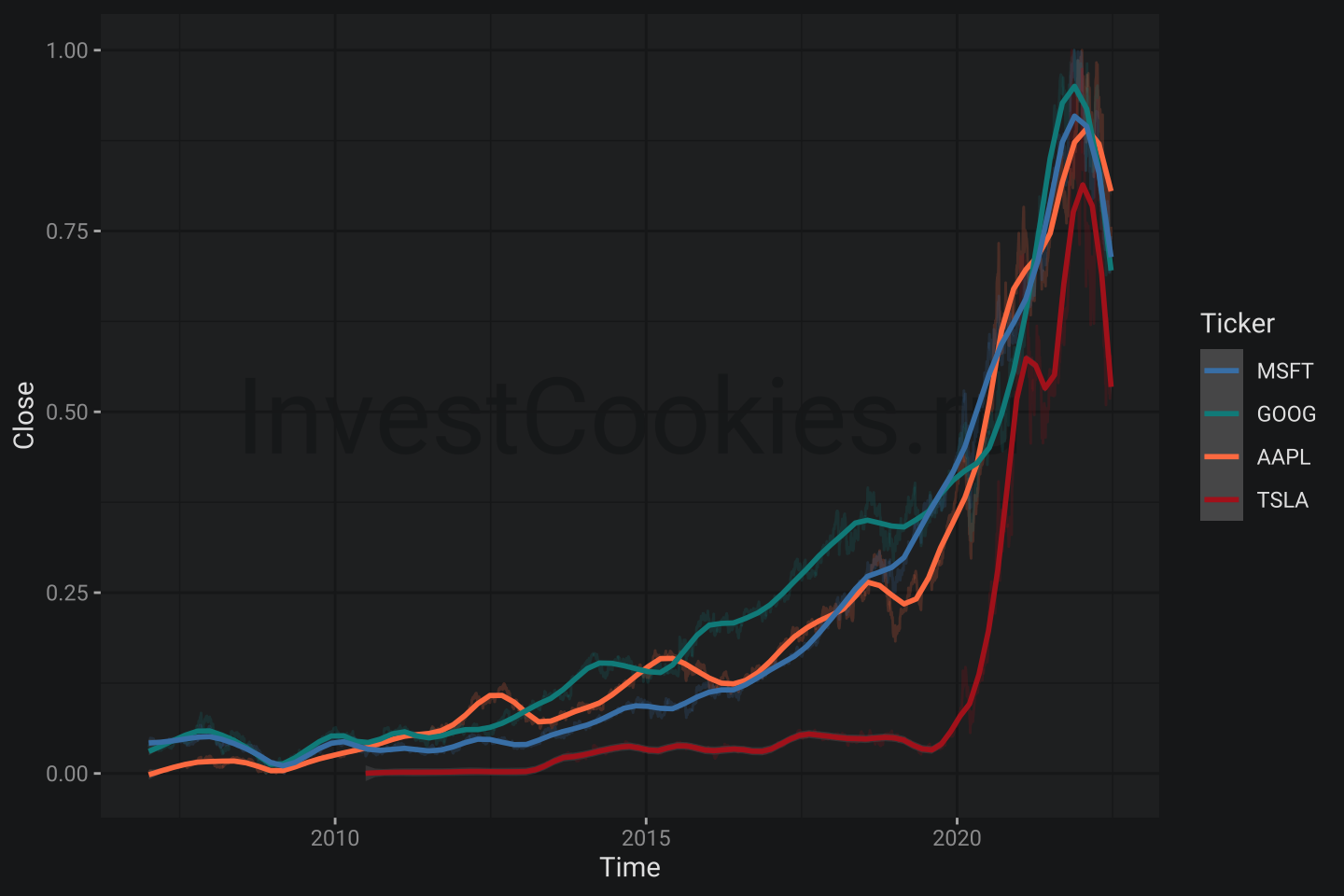 Получилось что-приятное глазу с чем уже можно работать, но я на этом не собираюсь останавливаться! Всем известно, что нет предела совершенства и соответствующему количеству рюшек с кружавчеками на графиках.
Получилось что-приятное глазу с чем уже можно работать, но я на этом не собираюсь останавливаться! Всем известно, что нет предела совершенства и соответствующему количеству рюшек с кружавчеками на графиках.
Антипаттерн 🌚
Прежде чем наращивать визуальное наполнение предыдущего графика нужно рассказать, что такое антипаттерн для ggplot2 и почему он может быть тоже полезен. Представим, что с ggplot2 работает человек, привыкший использовать тот же matplotlib т.е. использовать широкий формат таблички. Собственно такой формат подготовлен ниже:
tickers2 <- tickers1 %>%
select(Ticker, Time, Close) %>%
pivot_wider(id_cols = Time, names_from = Ticker, values_from = Close)
# Табличка с рюшечками и кружавчиками
slice_sample(tickers2, n = 100) %>% # 100 случайных наблюдений
datatable(style = 'bootstrap4', extensions = 'Responsive', options = list(pageLength = 10),
caption = "Котировки технологических гигантов") %>%
formatRound(c(2:5), digits = 2, mark = " ")
Пришлось выкинуть колонки с прочими значениями и оставить только Close значения, которые теперь имеют названия тикеров. Получается такая привычная excel-стайл табличка. Можно ли построить график для таких данных? Конечно можно:
ggplot(tickers2) +
geom_line(aes(Time, GOOG), col = "steelblue") + # первый тикер
geom_line(aes(Time, AAPL), col = "darkcyan") + # второй тикер
geom_line(aes(Time, TSLA), col = "coral") + # третий тикер
geom_line(aes(Time, MSFT), col = "firebrick") # ну вы уже поняли, что это кривовато ...
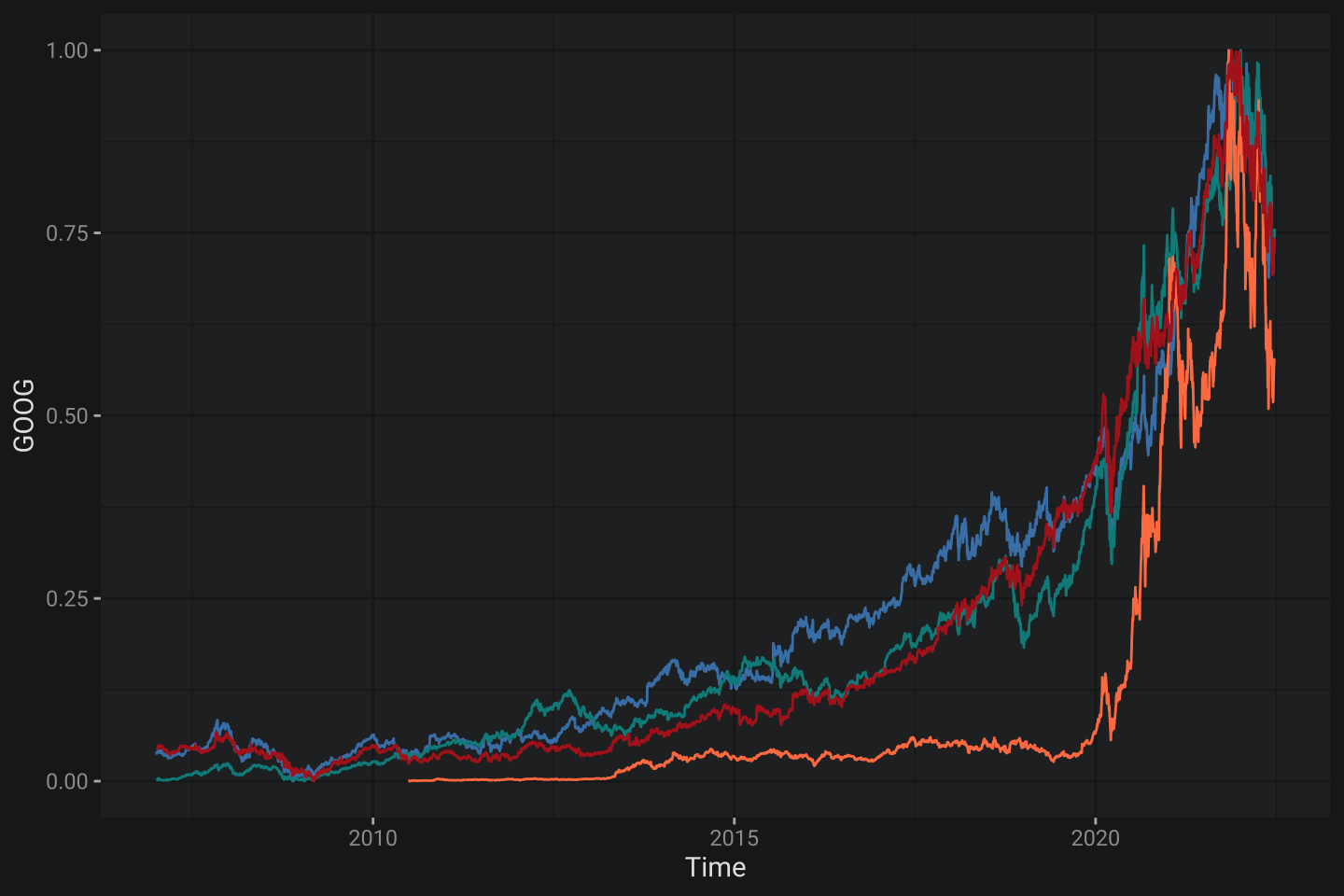 В данном случае по очереди добавлен каждый график, что потребовало от меня более обильного стучания по клавиатуре. Соответственно, если нам нужно добавить 100 тикеров то мы будем писать ручками дополнительные 100 строчек кода. Это очень увлекательное приключение, которое я оставлю в качестве домашнего задания. Еще печальнее ситуация с легендой, которая просто пропала и требует ручного добавления. К счастью у меня есть рецепт как с этим быть:
В данном случае по очереди добавлен каждый график, что потребовало от меня более обильного стучания по клавиатуре. Соответственно, если нам нужно добавить 100 тикеров то мы будем писать ручками дополнительные 100 строчек кода. Это очень увлекательное приключение, которое я оставлю в качестве домашнего задания. Еще печальнее ситуация с легендой, которая просто пропала и требует ручного добавления. К счастью у меня есть рецепт как с этим быть:
ggplot(tickers2) +
geom_line(aes(Time, GOOG, col = "GOOGLE")) +
geom_line(aes(Time, AAPL, col = "APPLE")) +
geom_line(aes(Time, TSLA, col = "TESLA")) +
geom_line(aes(Time, MSFT, col = "Microsoft"))
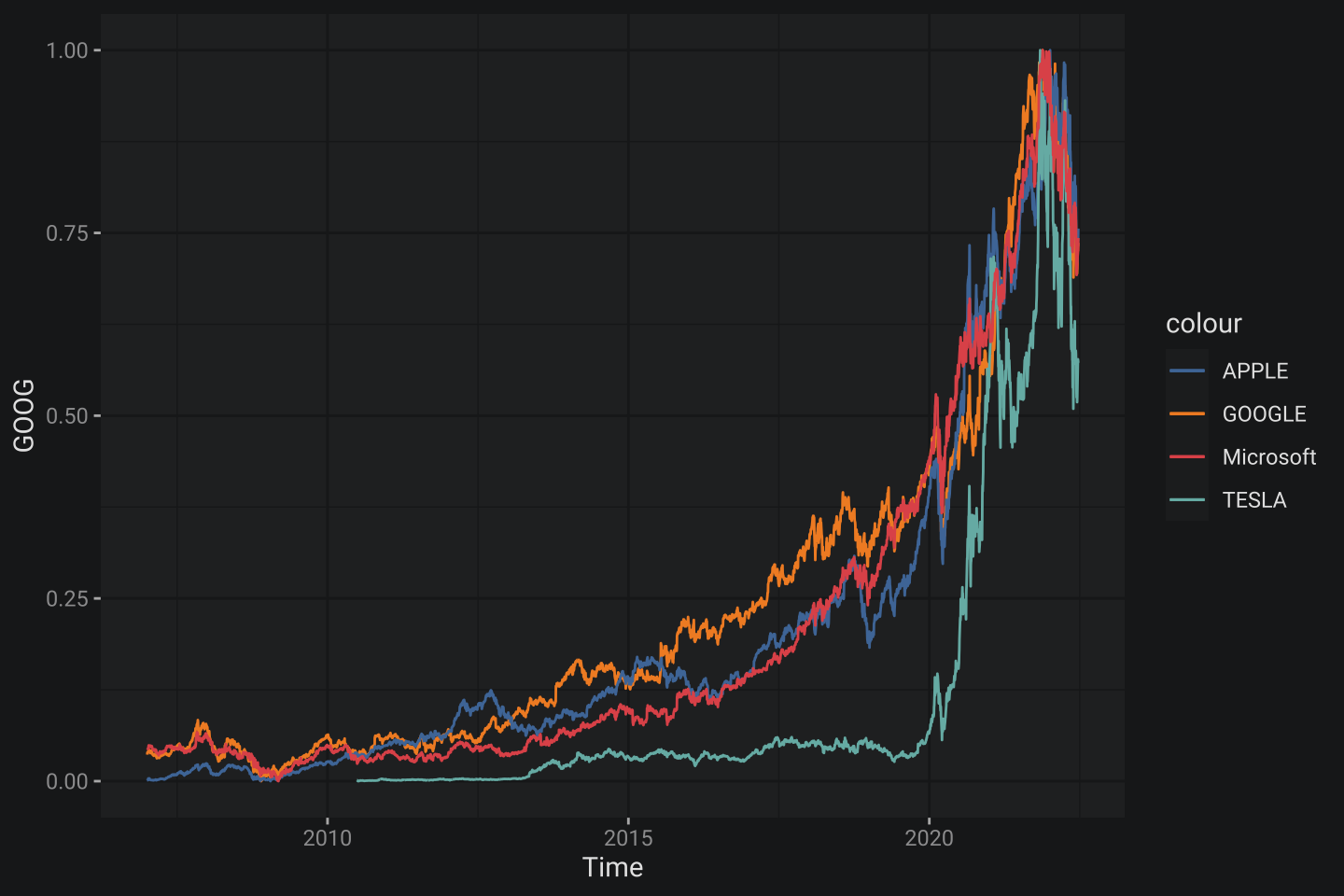 Очень важно обратить внимание на то, что я внес название тикеров под
Очень важно обратить внимание на то, что я внес название тикеров под aes(), что означает динамическое, а не статическое управление цветами.
Теперь легенда появилась и хотелось бы задать цвета, которые мы определили ранее для чего я также буду использовать scale_color_manual(). К сожалению, нужно создать новый вектор col2 и присвоить ему имена в виде имен компаний, а не коротких тикеров чтобы в легенде были красивые имена, а не обрубки:
# вектор брендированных цветов с красивыми именами
cols2 <- c("steelblue", "darkcyan", "coral", "firebrick") %>% set_names(tick_names)
ggplot(tickers2) +
geom_line(aes(Time, GOOG, col = "GOOGLE")) +
geom_line(aes(Time, AAPL, col = "APPLE")) +
geom_line(aes(Time, TSLA, col = "TESLA")) +
geom_line(aes(Time, MSFT, col = "MICROSOFT")) +
scale_color_manual(values = cols2) # указание цветов
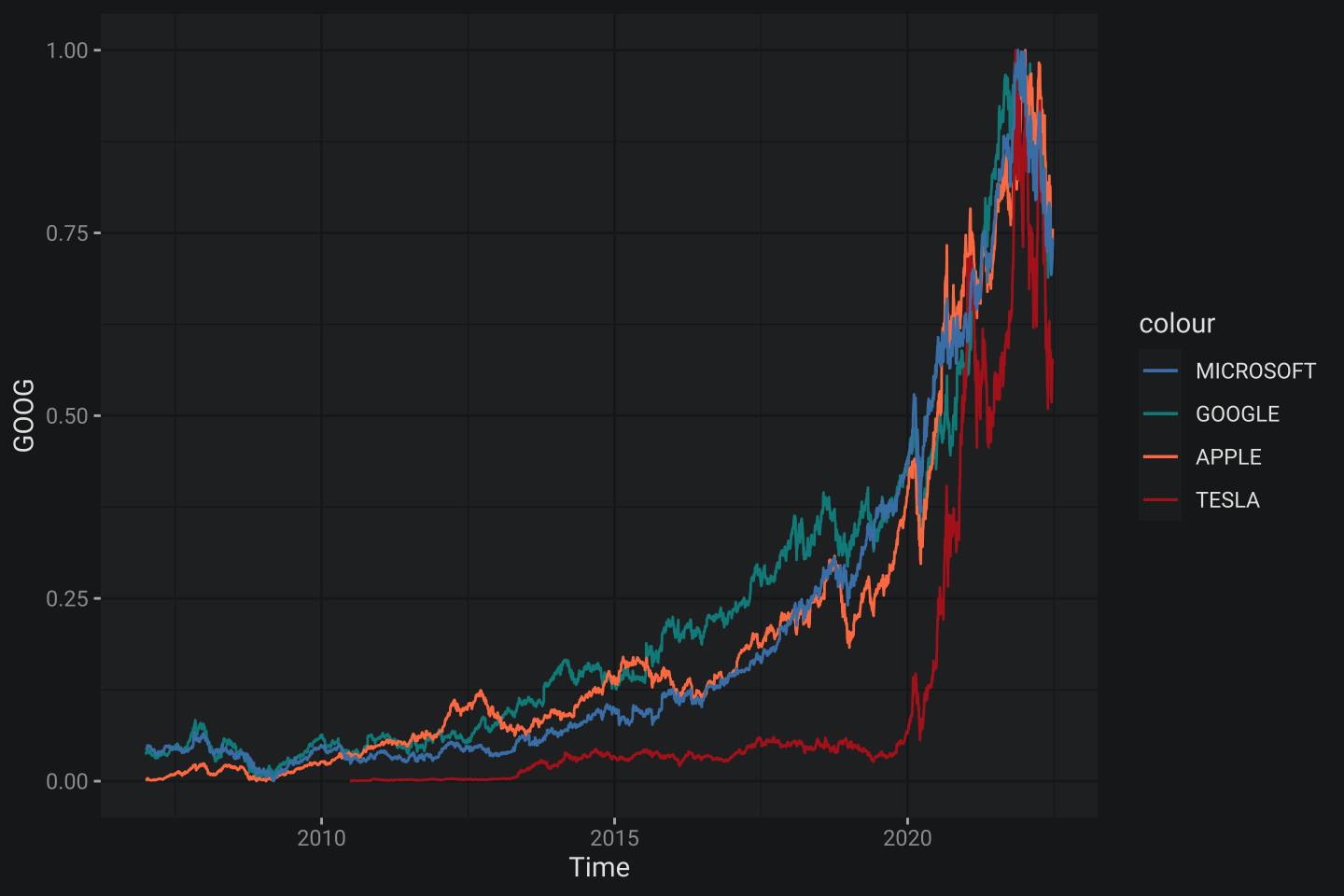 Получилось практически тоже самое, что и при использовании паттерна, но с большим количеством усилий. Естественно, если нужно будет добавить сглаженные кривые, то придется добавить еще четыре строчки кода, что также выглядит громоздко по сравнению с правильным подходом.
Получилось практически тоже самое, что и при использовании паттерна, но с большим количеством усилий. Естественно, если нужно будет добавить сглаженные кривые, то придется добавить еще четыре строчки кода, что также выглядит громоздко по сравнению с правильным подходом.
Существует иной метод ручного указания цветов и подписей легенды через scale_color_identity(), но лично я его считаю еще более громоздким:
ggplot(tickers2) +
geom_line(aes(Time, GOOG, col = "steelblue")) +
geom_line(aes(Time, AAPL, col = "darkcyan")) +
geom_line(aes(Time, TSLA, col = "coral")) +
geom_line(aes(Time, MSFT, col = "firebrick")) +
scale_color_identity(breaks = c("steelblue", "darkcyan", "coral", "firebrick"),
labels = c("GOOGLE", "APPLE", "TESLA", "MICROSOFT"),
guide = "legend")
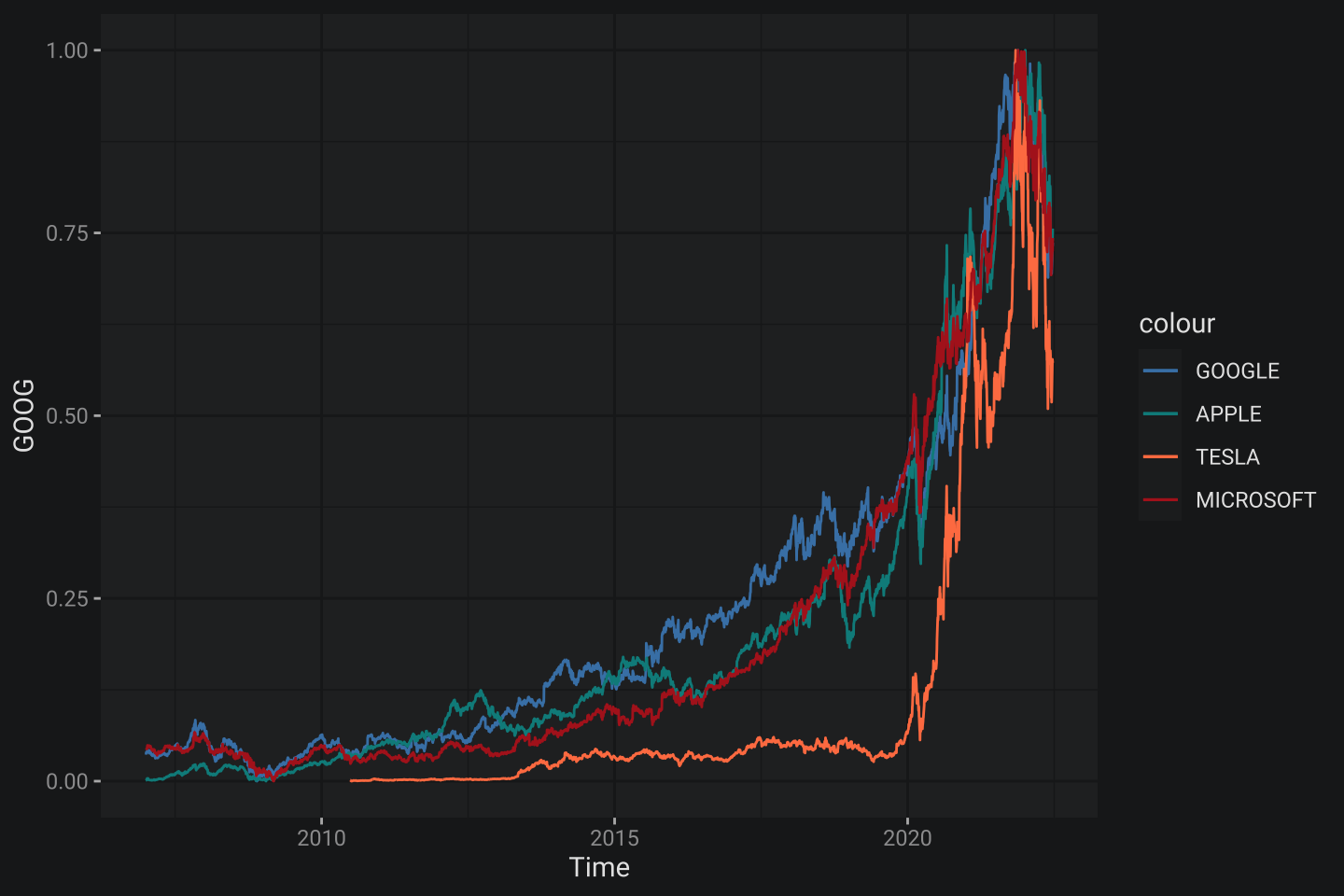
Все вместе 💪
Теперь когда стало понятно, что позволяет паттерн и антипаттерн я буду комбинировать эти два подхода для того чтобы добиться максимального эффекта от графика. План будет следующий:
- Добавить информацию об объемах торгов
- Добавить информацию о внутредневной волатильности. В качестве оценки внутридневной волатильности будет взята разница между значениями
HighиLow
Для построение графиков будет использован паттерн с разделением по цветам тикеров и антипаттерн для добавления объемов и внутридневной волатильности на один график. Для того чтобы показать все на одном графике будут использованы следующие функции:
stat_smooth(geom = 'area')– для построение сглаженного графика областейguides(color = guide_legend(label.position = "bottom"))– это конструкция, которая позволяет тонко настраивать способ визуализации легенды, в данном случае подписи легенды будут опущены внизscale_y_continuous()– для указания красивых процентиков на шкалеfacet_grid()– для построение фасетного графика и эта тема заслуживает отдельной заметки поэтому не будут сейчас подробно на ней останавливаться
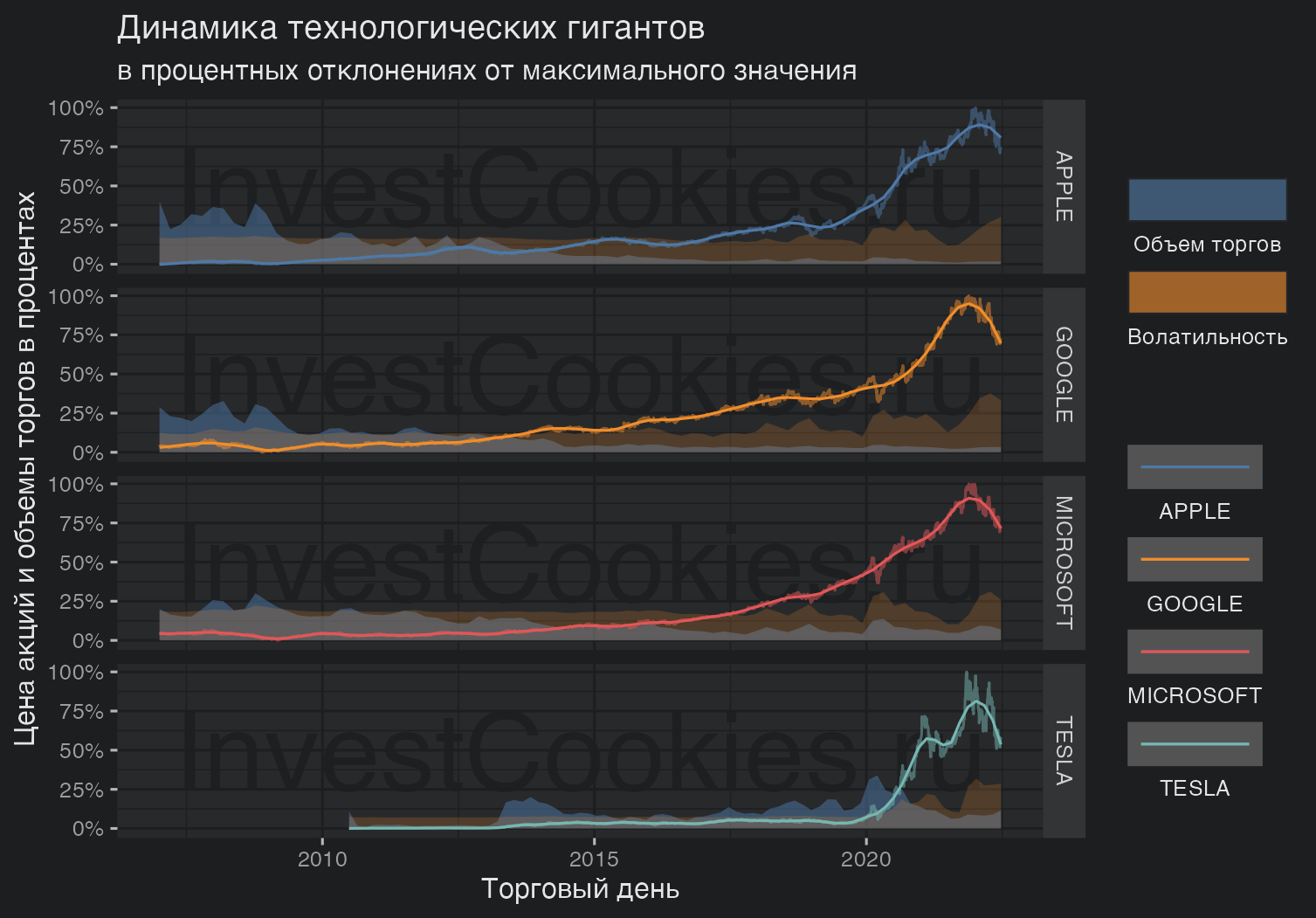
tickers1 %>%
mutate(Spread = scales::rescale(High - Low, to = c(0, 1))) %>% # переменная внутридневной волатильности
ggplot(aes(Time)) +
annotate("text_npc", npcx = .5, npcy = .5, label = "InvestCookies.ru",
color = "#1D1E20", alpha = .9, size = 15) + # сново брендирование
stat_smooth(geom = 'area', aes(y = Volume, fill = "Объем торгов"),
method = 'loess', span = .05, alpha = .5, formula = 'y ~ x') + # объемы торгов
stat_smooth(geom = 'area', aes(y = Spread, fill = "Волатильность"),
method = 'loess', span = .05, alpha = .2, formula = 'y ~ x') + # внутридневная волатильность
geom_line(aes(y = Close, col = Ticker), alpha = .5) + # график котировок
stat_smooth(aes(y = Close, col = Ticker), span = .1,
method = 'loess', formula = 'y ~ x', size = .5) + # сглаженный график котировок
scale_color_manual(values = my_pal, labels = tick_names) + # ставим красивые цвета и имена на легенду
scale_fill_manual(values = c("Объем торгов" = my_pal[1], "Волатильность" = my_pal[2])) +
scale_y_continuous(labels = scales::percent) +
guides(color = guide_legend(label.position = "bottom"),
fill = guide_legend(label.position = "bottom")) + # очень полезная конструкция управления легендой
facet_grid(Ticker~., labeller = labeller(Ticker = tick_names)) +
labs(title = "Динамика технологических гигантов",
subtitle = "в процентных отклонениях от максимального значения",
x = "Торговый день", y = "Цена акций и объемы торгов в процентах", fill = "", col = "")
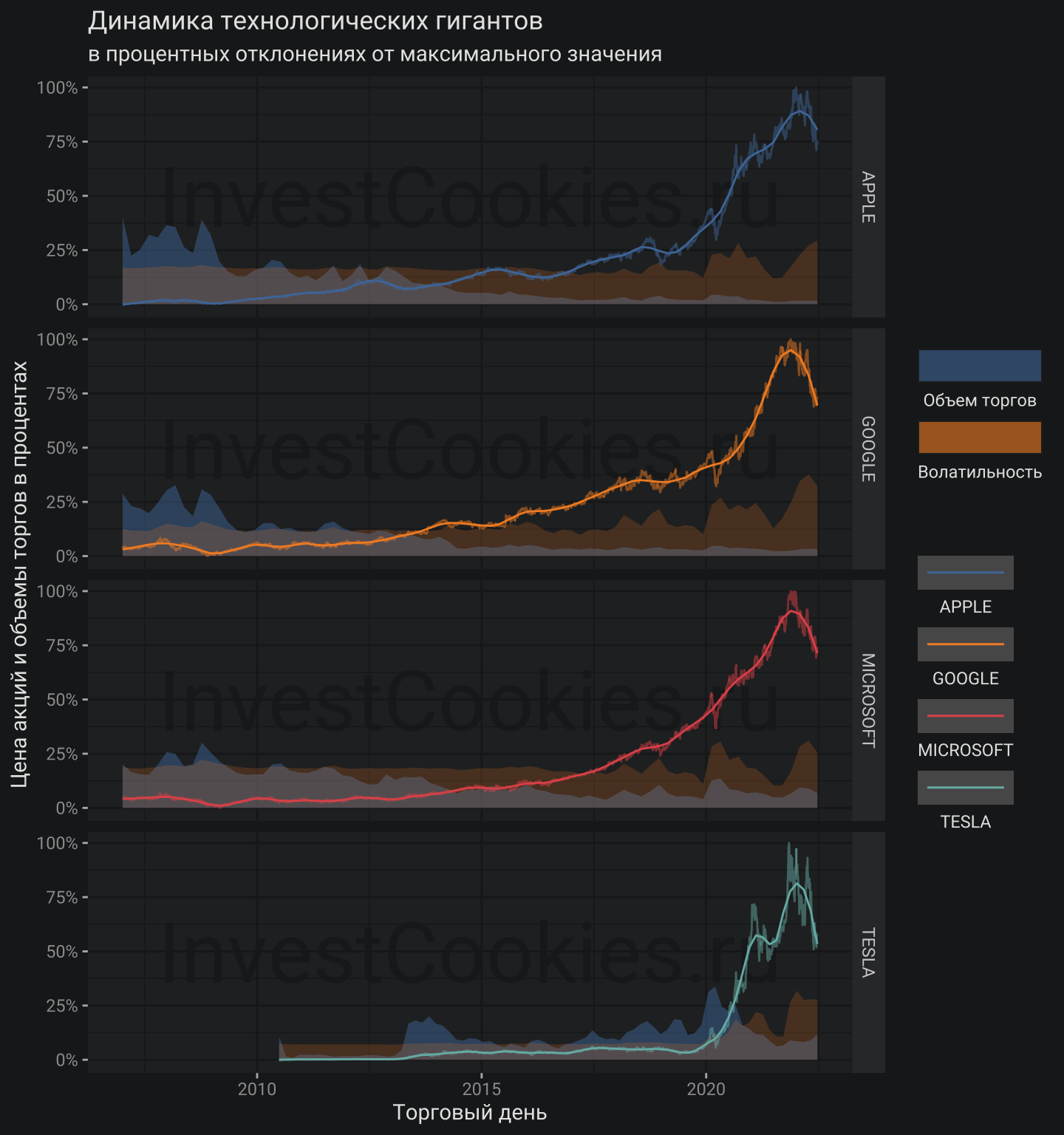 Теперь график можно проанализировать и сделать некоторые выводы:
Теперь график можно проанализировать и сделать некоторые выводы:
- Все технологические гиганты синхронно бурно росли до 2022 года и теперь, как известно, синхронно бурно падают, причины чего всем хорошо известны 🎢
- Большие дяди с большими деньгами закупались технологическими гигантами до 2014 года, а в случае Тесла большие объемы закупок были в 2014 и 2020 годах. Похоже, что разгон цен на отрезке с 2014 года по 2022 год был связан с розничным шоппингом физиков 🛒
- Падение 2022 года происходит на относительно небольших объемах и при высокой внутридневной волатильности т.е. большие дяди не торопятся выходит из этих компаний, а вот розница похоже в панике распродает все, что накупила в период с 2014 года по 2022 год. Этакая маленькая американская трагедия 😢
Итоги 👐
Нужно подытожить самое важное по поводу работы с легендами в ggplot2:
- Правильный паттерн – использование табличек длинного формата, когда множество колоночек собираются в одну стопочку
- Антипаттерн – попытка построить график на табличке широкого формата, что требует большого количества ручных манипуляций, но дает высокий уровень управления
- Иногда удобно использовать сочетание паттерна и антипаттерна для построение графиков временных рядов, которые нужно расположить рядом для наглядности
- Для управления структурой легенды нужно использовать
scale_color_*илиscale_fill_* - Для управления легендой антипаттерна нужно явно указывать имена графиков внутри
aes() - Для тонкого управления визуальными настройками легенды нужно использовать конструкцию
guides(color = guide_legend()), которая содержит массу полезных опций
Простой способ узнать о новых публикациях – подписаться на Telegram-канал: