
О продолжении ⏩
В прошлой заметке я принялся сравнивать безопасность на дорогах Турции и РФ, приводя конкретные цифры по травматизму и смертности на дорогах двух стран. Напомню, что вопросы относительно степени влияния урбанизации и климата на риски ДТП (травматизм и смертность) остались за рамками предыдущей заметки.
Статья привлекла интерес и я очень признателен читателям за обратную связь, которая – является источником идей для дальнейшего анализа. Конечно не вся критика на заметку была конструктивной. В частности, некоторые читатели формулировали обратную связь в следующем ключе:
Неправильно ты, дядя Фёдор, бутерброд ешь… данные приготовил неправильно, считать нужно было по другому, графики непонятные. Я бы сам показал как нужно, да у меня данных нет.
Специально для таких читателей акцентирую еще раз: все данные, которые используются мной – являются публичными. Я не хакер и не взламываю защищенные серверы ГОСАВТОИНСПЕКЦИИ. Более того, я делаю все возможно для того чтобы у любого желающего была возможность перепроверить все расчеты или поиграть с данными самостоятельно. Именно поэтому исходный код обработки данных и построения диаграмм с комментариями можно найти в самом низу, если вы читаете заметку на https://investcookies.ru/. Если вы читаете данную заметку на агрегаторе, то можно пройти по ссылке на первоисточник и найти все там.
Регионы 🏘️
Предметом претензий в мой адрес одного читателя стало то, что я сравнивал показатели безопасности регионов РФ с Турцией в целом. Напомню, что дороги Санкт-Петербурга и Москвы были существенно безопаснее чем дороги Турции в целом. По этому поводу у меня есть две новости: хорошая и плохая. Хорошая новость заключается в том, что мне удалось найти статистику по ДТП в разрезе регионов не только для РФ, но и для Турции. Плохая – Турецкая статистика в разрезе регионов, предоставлена только за последние два года и анализ какой либо динамики будет затруднительным. Напомню, что динамика в РФ имела положительную тенденцию тогда как для Турции такой тенденции не было обнаружено.
Тем не менее, сравнение регионов Турции, например, с городами федерального значения РФ – также не является вполне честным так как города не включают протяженные трассы, расположенные в областях, которые в свою очередь являются источником повышенной угрозы. Чтобы сравнение было честным пришлось объединить Ленинградскую область с Санкт-Петербургом, а Москву с Московской областью и рассчитать статистические показатели для таких квази-регионов.

Получившийся рейтинг наглядно говорит, что травматизм на дорогах всех регионов Турции существенно превышает травматизм в регионах РФ. Смертность на дорогах Краснодарского края самая высокая, второе место по этому антипоказателю занимает излюбленное место российских релокантов – Анталия. Наиболее безопасным городом по риску смертности – является Стамбул и далее следует Москва, которую можно назвать лидером по совокупности рисков ДТП (травматизм и смертность).
Урбанизация 🏡
Следующий вопрос, вызвавший горячие обсуждение можно сформулировать так:
Почему крупные города и агломерации с высоким уровнем урбанизации и плотностью населения (Москва, Санкт-Петербург, Стамбул) имеют значительно лучшие показатели рисков ДТП?
Дело конечно не в плотности населения или уровне урбанизации, а скорее в уже упомянутой протяженности скоростных дорог и средствах обеспечения безопасности на этих дорогах. К сожалению, статистики по количеству дорог и тем более интенсивности движения в городской, сельской местности у меня нет, но вот процент урбанизации можно вычислить. Очевидно, что степень урбанизация будет связана с протяженностью дорог в городской черте, хотя конечно нельзя такую связь назвать на 100% точной. В любом случае, приходиться работать с тем, что есть.
Далее я буду использовать методический прием, который применялся мной в реальных боевых проектах. Не знаю почему, но у многих рвет шаблоны, когда я вместо привычных временных рядов перехожу на совокупность наблюдений, привязанных к объектам реального мира. В данном случае в моем распоряжении имеется статистика по регионам РФ, каждый из которых характеризуется своей смертностью и травматизмом и также своим уровнем урбанизации. Почему бы внутри этой совокупности не поискать взаимосвязь?
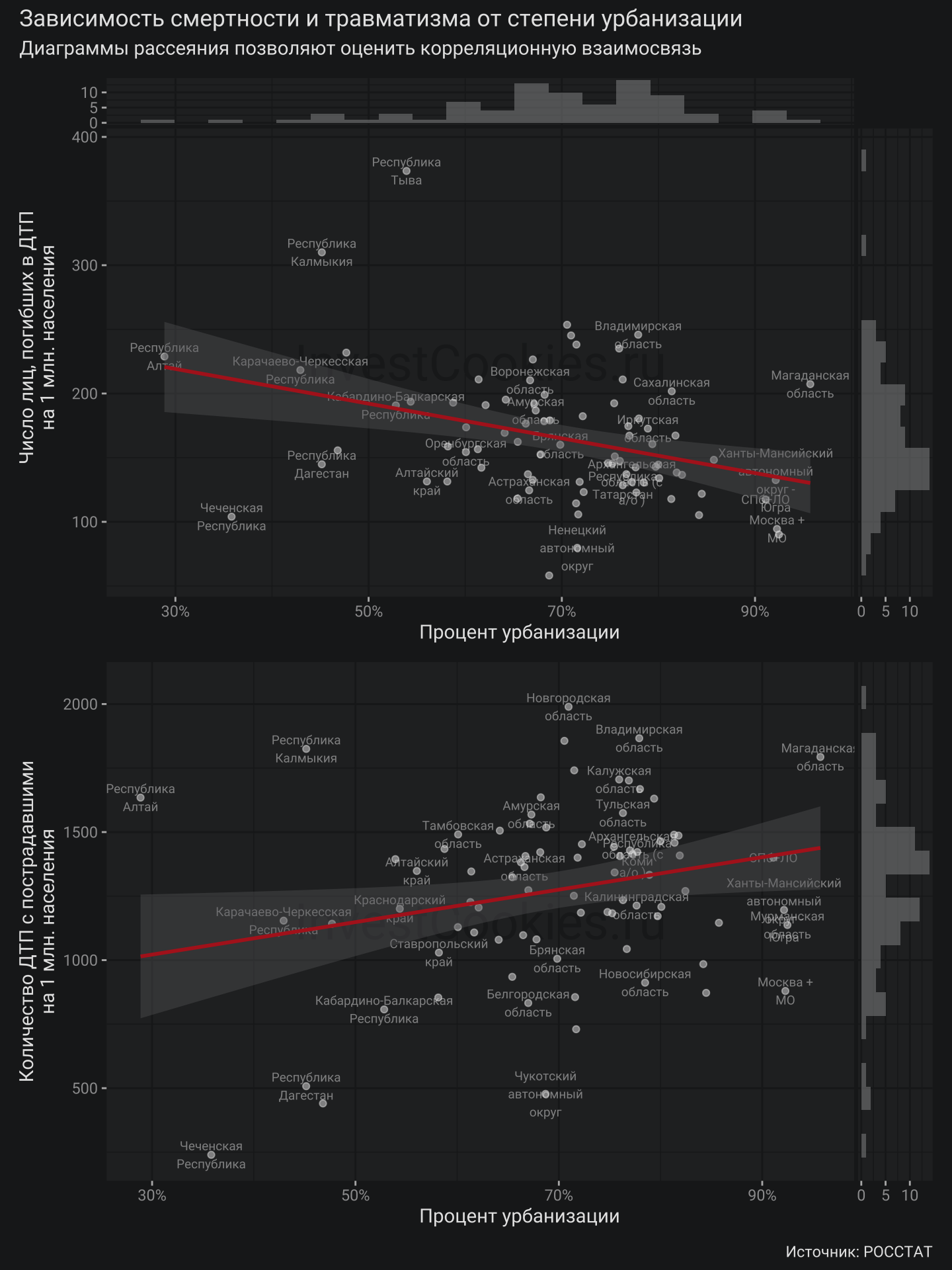
На диаграммах рассеяния визуально можно заметить направленность “облака” значений в ту или иную сторону, что означает наличие взаимосвязи или по научному – корреляции. Также были прикреплены гистограммы распределений смертности (верхняя диаграмма справа), травматизма (нижняя диаграмма справа) и урбанизации (верхняя и диаграмма сверху). Это сделано для того чтобы визуально оценить нормальность распределения величин в которых ищется взаимосвязь. В данном случае есть все основания полагать, что нормальное распределение отсутствует и поэтому для количественной оценки взаимосвязи показателей нужно использовать соответствующие методы. Далее я буду использовать достаточно простой и эффективный способ представления взаимосвязи – матрицу корреляций:
Травматизм Смертность Урбанизация Травматизм 1.00 0.58 0.19 Смертность 0.58 1.00 -0.34 Урбанизация 0.19 -0.34 1.00
Для тех, кто не знаком с таким представлением информации можно дать достаточно простые интерпретации. По диагонали матрицы стоят единички, что означает абсолютную взаимосвязь показателя с самим собой. Из этого факта следует, что наибольшей взаимосвязью обладают два показателя со значением корреляции равным единице. Если корреляция равна минус одному, то такие показатели абсолютно противоположны друг другу. Если корреляция равна нулю, то связи между показателями нет. Естественно, в реальности 1 или -1 не встречаются то есть если, например, замерять показание скорости на спидометре автомобиля, а потом посчитать пройденный километраж каждого отрезка и сравнить с показателями одометра того же автомобиля, то будет небольшое расхождение в силу ошибок замеров и погрешности датчиков автомобиля. В этом случае корреляция будет 0.95 - 0.98, но никак не единица. Значения, расположенные не по диагонали матрицы показывают корреляцию между разными показателями. В данном случае наиболее интересной – является некоторая зависимость между показателем смертности и степенью урбанизации, которая равна -0.34 то есть чем выше степень урбанизации – тем ниже смертность. Важно помнить, что в этом утверждении не указанна причинность: речь идет лишь о взаимосвязи. Старая шутка из среды статистики по этому поводу звучит так:
В городе N-ске была выявленная высокая корреляции между количеством пожаров и количеством пожарных станций из чего был сделан вывод, что увеличение количества пожарных станций приводит к увеличению пожаров в городе 🚒🔥
В конечном счет допускаю, что количество скоростных дорог (показатель, который отсутствует в статистических данных) может одновременно влиять и на урбанизацию и также на смертность на дорогах. Ох уж эта наука – никогда не дает простых ответов на сложные вопросы 🥸 Получается, что сравнение РФ с некоторыми высокоурбанизированными странами западной Европы (Нидерланды – 93%, Бельгия – 98%, Дания – 88% и пр.) будет носить сомнительный характер так как, вероятно, дело будет не в манере вождения или развитости/недоразвитости инфраструктуры, а в силу объективных отличий бескрайних просторов России и уютно-компактной Европы. При этом увеличение урбанизации на 1% будет очень грубо соответствовать сокращению смертности на 1.35 человека на миллион в случае сравнения с Нидерландами можно говорить о дельте в 24.4 погибших на миллион, что достаточно ощутимо, если учесть значение смертности в РФ за 2022 год - 97 погибших на миллион.
Для тех, кто хочет еще сильнее погрузиться в статистические дебри предлагаю посмотреть разделы со статистическими тестами.
Статистический тест
Как уже упоминалось, распределение сопоставляемых показателей – не является нормальным, а следовательно необходимо использовать непараметрический тест, например тест Spearman:
##
## Spearman's rank correlation rho
##
## data: impact$death_rate and impact$urban_rate
## S = 122740, p-value = 0.002144
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## -0.3358583
Результат теста показывает значение p-value = 0.002144, которым так любят козырять в медицинских исследованиях. К сожалению, часто его неправильно интерпретируют. Малое значение p-value т.е. ниже некоторого критического значения (обычно 0.05 или 0.01), говорит о том, что нулевая гипотеза должна быть отвергнута. А нулевая гипотеза всегда строится от отрицания, интересующего исследователя факта. В данном случае нулевая гипотеза звучит так: Взаимосвязь между смертностью и урбанизацией равна нулю. Низкий p-value говорит о том, что это утверждение можно отвергнуть, а вот альтернативная гипотеза наоборот не отвергается: Взаимосвязь между смертностью и урбанизацией не равна нулю. p-value не показывает силу взаимосвязи, а показывает уверенность установления факта взаимосвязи. Сила взаимосвязи определяется коэффициентом корреляции т.е. в данном примере приблизительно в 1/3 случаев смертности на дорогах может быть связана с урбанизацией.
Для того чтобы оценить эластичность показателя смертности по урбанизации можно построить простую модель линейной регрессии для оценки коэффициентов эластичности:
##
## Call:
## lm(formula = impact$death_rate ~ impact$urban_rate)
##
## Residuals:
## Min 1Q Median 3Q Max
## -108.657 -30.548 -6.794 19.457 186.669
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 259.74 29.22 8.890 1.45e-13 ***
## impact$urban_rate -135.26 41.15 -3.287 0.00151 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 47.2 on 80 degrees of freedom
## Multiple R-squared: 0.119, Adjusted R-squared: 0.108
## F-statistic: 10.8 on 1 and 80 DF, p-value: 0.001506
Полученная модель не то чтобы обладает хорошей предсказательной способностью, но коэффициенты модели статистически значимы, а следовательно можно делать выводы о наличие зависимости и прикидывать насколько изменится смертность при росте уровня урбанизации.
Климат 🌡️
Другой популярной гипотезой о факторах смертности на дорогах, как выяснилось, стал климат, о котором я также упоминал в первой заметке. Следует принять, что климат – есть понятие растяжимое. О чем идет речь? О температуре, о количестве осадков или о конфигурации того и другого?
Я смог найти не так много климатических данных в открытом доступе. Для городов РФ удалось обнаружить данные на сайте ГИДРОМЕТЦЕНТРА РФ, хранящиеся в весьма замысловатом виде и требующие навыков черной магии для работы с ними 🪄 Поэтому если кто-то будет интересоваться как я это сделал – смотрите исходный код и оставляйте комментарии, если что-то не понятно.
Для изучения влияния климата я использовал тот же подход, что и для урбанизации, а именно для статистики регионов РФ искалась взаимосвязь рисков ДТП с показателями средней температуры и количеством осадков.

В получившихся картинках едва можно рассмотреть какую-либо зависимость. Только связь осадков с травматизмом выглядит хоть сколько-нибудь обнадеживающей. Количественная оценка взаимосвязи следует из матрицы корреляции:
Смертн. Травм. ℃ ночь ℃ день Осадки Пасмур. Смертн. 1.00 0.58 0.16 0.21 0.13 -0.04 Травм. 0.58 1.00 0.02 -0.09 0.37 0.34 ℃ ночь 0.16 0.02 1.00 0.91 0.29 0.15 ℃ день 0.21 -0.09 0.91 1.00 0.11 -0.08 Осадки 0.13 0.37 0.29 0.11 1.00 0.70 Пасмур. -0.04 0.34 0.15 -0.08 0.70 1.00
Действительно, количество осадков имеет корреляцию величиной 0.37 с показателем травматизма. Если предположить, что среднемесячное количество осадков увеличится на 10 мм, то это приведет к увеличению количества ДТП с пострадавшими на 125 человека на 1 миллион населения региона.
Статистический тест
Тест на значимость связи травматизма с количеством осадков:
##
## Spearman's rank correlation rho
##
## data: impact_climate$injury_rate and impact_climate$mean_rain
## S = 36123, p-value = 0.0002471
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.4192086
Теста отвергает нулевую гипотезу в пользу альтернативной: корреляция между показателями не равна нулю.
Далее простая модель линейной регрессии для количественной оценки эластичности травматизма и количества осадков:
##
## Call:
## lm(formula = injury_rate ~ mean_rain, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1083.96 -217.28 -23.21 200.00 1525.72
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 870.267 177.475 4.904 5.88e-06 ***
## mean_rain 12.519 3.721 3.364 0.00125 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 384.9 on 70 degrees of freedom
## Multiple R-squared: 0.1392, Adjusted R-squared: 0.1269
## F-statistic: 11.32 on 1 and 70 DF, p-value: 0.001248
Как и в случае с урбанизацией, предсказательную способность, полученной модели сложно назвать выдающейся. Тем не менее, коэффициенты связи травматизма и количества осадков – являются значимыми, а следовательно их можно использовать для количественных оценок эластичности.
Итоги 🍪
Кратко и сжато о результатах второй части исследования рисков ДТП на дорогах РФ и Турции:
- В сравнении популярных регионов Турции и РФ по безопасности на дорогах лидерами можно назвать столицы: Москву и Стамбул, а вот аутсайдерами будут Анталия и Краснодарский край
- Уровень урбанизации влияет на безопасность на дорогах: 1% роста урбанизации может спасти 1.35 человека на миллион жителей региона
- Климатические условия региона не оказывают влияния на смертность но в некоторой степени влияют на травматизм: рост количества среднемесячных осадков на 10мм ведет к увеличению количества ДТП с пострадавшими на 125 человек на 1 млн. населения
Оставайтесь бдительными на дорогах 🙏
Исходный код заметки
library(tidyverse) # набор библиотек по принципу все-в-одном
library(fedstatAPIr) # пакет для выгрузки данных с РОССТАТА
library(patchwork) # для построения композиции диаграмм
library(rvest) # для сбора данных с публичных сайтов
library(ggside) # для построения боковых гистограмм
ru_injuries0 <- fedstat_data_load_with_filters("36234") # сведения по ДТП с пострадавшими
ru_deaths0 <- fedstat_data_load_with_filters("36233") # сведения по погибшим в ДТП
ru_population0 <- fedstat_data_load_with_filters("31557") # сведения по численности населения РФ
# Подготовка сведений по дорожным происшествиям в РФ в разрезе регионов
## Некоторые перекодировочные справочники для нормализации сведений, предоставляемые РОССТАТом
months <- c("январь", "февраль", "март", "апрель", "май", "июнь", "июль", "август", "сентябрь", "октябрь", "ноябрь", "декабрь")
fix_rgn <- c("030000000001" = "Краснодарский край", "410000000001" = "СПб+ЛО", "400000000001" = "СПб+ЛО",
"460000000001" = "Москва + МО", "450000000001" = "Москва + МО", "670000000001NA" = "Крым",
"670000000001" = "Крым", "350000000001NA" = "Крым", "350000000001" = "Крым",
"643" = "Российская федерация")
fix_rgn_code <- c("400000000001" = "410000000001", "450000000001" = "460000000001", "670000000001NA" =
"350000000001", "670000000001" = "350000000001", "350000000001NA" = "350000000001")
fix_rgn_name <- c("г. Санкт-Петербург" = "СПб+ЛО", "Ленинградская область" = "СПб+ЛО",
"Московская область" = "Москва + МО", "г. Москва" = "Москва + МО" )
## Подготовка сведений по населению регионов с учетом структуры: городского и местного населения
ru_population <- mutate(ru_population0, rgn = str_replace(s_OKATO_code, "0$", "01")) %>%
filter(Time > 2009 & s_OKTMO == "Раздел 1. Муниципальные образования субъектов Российской Федерации") %>%
mutate(population = as.integer(ObsValue), year = as.integer(Time)) %>%
pivot_wider(id_cols = c(year, rgn), names_from = c("s_mest", "s_mest_code"), values_from = "population") %>%
select(year, rgn, population = "все население_w2:p_mest:11", urban = "городское население_w2:p_mest:12", rural = "сельское население_w2:p_mest:13")
## Подготовка сведений по количеству ДТП с пострадавшими
injuries <- ru_injuries0 %>%
mutate(year = as.integer(Time),
month = str_remove(PERIOD, "январь-") %>% factor(levels = months) %>% as.numeric()) %>%
group_by(Time, p3.1) %>%
mutate(injury = as.integer(ObsValue) - lag(as.numeric(ObsValue), default = 0)) %>%
left_join(ru_population, by = c("year", "p3.1_code" = "rgn")) %>%
ungroup() %>%
select(year, month, injury, rgn = p3.1_code, rgn_name = p3.1)
## Подготовка сведений по количеству погибших в ДТП
deaths <- ru_deaths0 %>%
mutate(year = as.integer(Time),
month = str_remove(PERIOD, "январь-") %>% factor(levels = months) %>% as.numeric()) %>%
group_by(Time, p3.1) %>%
mutate(death = as.integer(ObsValue) - lag(as.numeric(ObsValue), default = 0)) %>%
left_join(ru_population, by = c("year", "p3.1_code" = "rgn")) %>%
ungroup() %>%
select(year, month, death, rgn = p3.1_code, rgn_name = p3.1)
## Агрегирование сведений из с уровня месячной детализации до уровня годовой
ru_stats <- deaths %>%
left_join(injuries, by = c("year", "month", "rgn", "rgn_name")) %>%
group_by(rgn, rgn_name, year) %>%
summarise(across(c("injury", "death"), sum), .groups = "drop") %>%
left_join(ru_population, by = c("year", "rgn"))
# Перекодировка регионов для нормализации сведений
ru_stats_fixed <- ru_stats %>%
mutate(rgn_name = recode(rgn, !!!fix_rgn)) %>%
filter(rgn_name %in% fix_rgn) %>%
group_by(rgn_name, year) %>%
summarise(across(c("injury", "death", "population"), sum), .groups = "drop") %>%
filter(rgn_name != "Крым") # статистика для Крыма не полная поэтому регион исключен из анализа
# Подготовка сведений по дорожным происшествиям в Турции в разрезе регионов
## Подготовка сведений по населению регионов
trk_population_rgn <- readxl::read_excel("data/trk_population_stat0.xls", sheet = "t1", skip = 3) %>%
select(rgn = 1, `2020` = 2, `2021` = 3) %>%
drop_na() %>%
pivot_longer(cols = 2:3, names_to = "year", values_to = "population") %>%
mutate(year = as.integer(year))
## Подготовка сведений по дорожным инцидентам. Часть 1
trk_traffic_rgn1 <- readxl::read_excel("data/trk_traffik_stat0.xls", sheet = "t3", skip = 5) %>%
select(rgn = 1, injury = 4, death = 5) %>%
drop_na()
## Подготовка сведений по дорожным инцидентам. Часть 2
trk_traffic_rgn2 <- readxl::read_excel("data/trk_traffik_stat0.xls", sheet = "t3", skip = 3) %>%
select(rgn = 11, injury = 14, death = 15) %>%
drop_na()
## Словарь для нормализации разных видов написания регионов
fix_trk_rgn <- c("K.Maraş" = "Kahramanmaraş", "Ş.Urfa" = "Şanlıurfa")
## Объединение сведений из двух частей
trk_traffic_rgn <- bind_rows(trk_traffic_rgn1, trk_traffic_rgn2) %>%
mutate(rgn_name = recode(rgn, !!!fix_trk_rgn)) %>%
left_join(filter(trk_population_rgn, year == 2021), by = "rgn")
# Подготовка данных по климату в разрезе регионов РФ
## Список ссылок по климатическим сведениям городов РФ
links <- c("https://meteoinfo.ru/categ-articles/15-climate-cat/klimaticheskie-normy/clim-towns",
str_glue("https://meteoinfo.ru/categ-articles/15-climate-cat/klimaticheskie-normy/clim-towns?start={1:8}0"))
climate_htmls <- map(links, read_html) # загрузка и парсинг страниц со сведениями городов
climate_tbls <- map(climate_htmls, ~html_table(., header = TRUE)) # извлечение таблиц из html-страниц
climate_cities <- map(climate_htmls, ~html_elements(., css = "h2") %>% html_text() %>% str_trim()) # извлечение названия городов из html-страниц
## Подготовка таблиц, скачанных из интернета
climate_tbl <- climate_tbls %>%
flatten() %>%
keep(~any("Месяц" %in% names(.))) %>%
map(~janitor::remove_empty(., which = c("rows", "cols"))) %>% # простой способ избавиться от полностью пустых колонок и строк
map(~rename(., month = 1, night_temp = 2, day_temp = 3, mean_rain = `Средняя сумма осадков`)) %>%
map(~rename_with(., ~str_replace(., "Среднее число днейс осадками более 0.1 мм|Среднее число дней с осадками более 0.1 мм", "mean_rain_day"))) %>%
map(~select(., month, night_temp, day_temp, mean_rain, mean_rain_day)) %>%
set_names(unlist(climate_cities)[-1]) %>%
map_dfr(~., .id = "city") %>%
filter(month != "Месяц") %>%
mutate(across(3:6, as.double))
## Выгрузка сведений по кодам регионов и городов для стыковки городов к регионам
OKATO <- read_html("https://classifikators.ru/okato") %>%
html_table() %>% .[[1]]
## Подготовка стыковочной таблицы городов с регионами
OKATO_code <- OKATO %>%
mutate(rgn = str_remove_all(Код, " "),
city = str_remove(`Административный центр`, "г ")) %>%
select(rgn, city) %>%
filter(city != "")
## Справочная таблица для нормализации названий городов
fix_cities <- c("Н.Новгород" = "Нижний Новгород", "С.-Петербург" = "Санкт-Петербург",
"Петропавловск- Камчатский" = "Петропавловск-Камчатский",
"Новгород" = "Великий Новгород")
## Подготовка климатических данных в разрезе регионов
climate <- climate_tbl %>%
mutate(city = recode(city, !!!fix_cities)) %>%
left_join(OKATO_code, by = "city") %>%
filter(!is.na(city)) %>%
mutate(rgn = str_replace(rgn, "0$", "01"), month = as.double(month))
# Регионы
## Объединение статистики Турции и РФ
traffik_all <- trk_traffic_rgn %>%
mutate(country = "Турция") %>%
filter(rgn %in% c("Antalya", "İzmir", "İstanbul")) %>%
bind_rows(filter(ru_stats_fixed, year == 2022 & rgn_name != "Российская федерация")) %>%
mutate(across(c("injury", "death"), ~.*1e6/population, .names = "{.col}_rate")) %>%
replace_na(list(country = "Россия"))
## Диграмма смертности
death_plt <- ggplot(traffik_all, aes(reorder(str_wrap(rgn_name, 5), death_rate),
death_rate, fill = country)) +
geom_col(alpha = .5) +
coord_flip() +
labs(x = "Регион", y = "Число лиц, погибших в ДТП\nна 1 млн. населения", fill = "Страна")
## Диграмма травматизма
injury_plt <- ggplot(traffik_all, aes(reorder(str_wrap(rgn_name, 5), injury_rate),
injury_rate, fill = country)) +
geom_col(alpha = .5) +
coord_flip() +
labs(x = "Регион", y = "Количество ДТП с пострадавшими\nна 1 млн. населения", fill = "Страна")
# Построение композиции диаграмм
death_plt + injury_plt +
plot_layout(guides = "collect") +
plot_annotation(subtitle = "Сравнение безопасности на дорогах Турции и РФ",
caption = "Источники: РОССТАТ, TURKSTAT")
# Урбанизация
# Подготовка сведений по безопасности на дорогах в разрезе регионов
impact <- ru_stats %>%
filter(str_count(rgn) !=3) %>%
mutate(rgn_title = recode(rgn, !!!fix_rgn), rgn_title = if_else(rgn_title %in% fix_rgn, rgn_title, rgn_name),
rgn_code = recode(rgn, !!!fix_rgn_code)) %>%
drop_na() %>%
group_by(rgn_title, rgn_code) %>%
summarise(injury_rate = sum(injury)*1e6/sum(population),
death_rate = sum(death)*1e6/sum(population),
urban_rate = sum(urban)/sum(population), .groups = "drop")
## Диаграмма по смертности
death_impct <- impact %>%
ggplot(aes(urban_rate, death_rate)) +
geom_point(alpha = .5) +
geom_text(aes(label = str_wrap(rgn_title, 10)), check_overlap = TRUE, size = 2.5, alpha = .5) +
scale_x_continuous(labels = scales::label_percent(), breaks = c(.1, .3, .5, .7, .9)) +
geom_xsidehistogram(alpha = .5, bins = 20) +
scale_xsidey_continuous(n.breaks = 4) +
geom_ysidehistogram(alpha = .5, bins = 20) +
scale_ysidex_continuous(n.breaks = 4) +
geom_smooth(method = "lm") +
labs(y = "Число лиц, погибших в ДТП\nна 1 млн. населения", x = "Процент урбанизации")
## Диаграмма по травматизму
impact_injury <- impact %>%
ggplot(aes(urban_rate, injury_rate)) +
geom_point(alpha = .5) +
geom_text(aes(label = str_wrap(rgn_title, 10)), check_overlap = TRUE, size = 2.5, alpha = .5) +
scale_x_continuous(labels = scales::label_percent(), breaks = c(.1, .3, .5, .7, .9)) +
geom_ysidehistogram(alpha = .5, bins = 20) +
scale_ysidex_continuous(n.breaks = 4) +
geom_smooth(method = "lm") +
labs(y = "Количество ДТП с пострадавшими\nна 1 млн. населения", x = "Процент урбанизации")
## Композиция диграмм по травматизму и смертности
death_impct/impact_injury +
plot_annotation(title = "Сравнение безопасности на дорогах Турции и РФ",
subtitle = "Диаграммы рассеяния позволяют оценить взаимосвзяь урбанизации и смертности",
caption = "Источник: РОССТАТ")
## Матрица корреляций для угроз на дорогах и степени урбанизации
select(impact, where(is.numeric), `Травматизм ` = injury_rate, `Смертность ` = death_rate, Урбанизация = urban_rate) %>%
cor(method = "spearman") %>% # непараметрический тест на корреляцию
apply(MARGIN = 2, \(x)round(x, 2)) %>%
emphatic::hl_mat(firatheme::scale_color_fira(continuous = TRUE))
## Тест на взаимозависимость
cor.test(impact$death_rate, impact$urban_rate, method = "spearman")
# Простая модель линейной регрессии для оценки коэффициентов
lm(impact$death_rate ~ impact$urban_rate) %>%
summary()
# Климат
## Подготовка сведений в месячной детализации для работы с климатическими данными
impact_climate <- deaths %>%
left_join(injuries, by = c("year", "month", "rgn", "rgn_name")) %>%
left_join(ru_population, by = c("year", "rgn")) %>%
mutate(rgn = recode(rgn, !!!fix_rgn_code), rgn_name = recode(rgn_name, !!!fix_rgn_name)) %>%
group_by(rgn, rgn_name, month) %>%
summarise(across(c(death, injury), ~sum(.)*1e6/mean(population), .names = "{.col}_rate"), .groups = "drop") %>%
left_join(climate, by = c("month", "rgn")) %>%
drop_na() %>%
filter(death_rate > 0) %>%
group_by(rgn_name) %>%
summarise(across(matches("rate|temp|rain"), mean))
# Диаграмма рассеяния для климатических факторов
impact_climate %>%
pivot_longer(c("death_rate", "injury_rate"), names_to = "rate_type", values_to = "rate_value") %>%
pivot_longer(matches("temp|rain"), names_to = "climate_type", values_to = "climate_value") %>%
ggplot(aes(climate_value, rate_value)) +
geom_point(alpha = .5) +
geom_smooth(method = "lm") +
facet_grid(rate_type ~ climate_type, scales = "free",
labeller = labeller(rate_type = c("death_rate"="Смертность", "injury_rate"="Травматизм"),
climate_type = c("night_temp"="Средняя месячная\nночная температура, °С",
"day_temp"="Средняя месячная\nдневная температура, °С",
"mean_rain"="Месячное\nколичество осадков, мм",
"mean_rain_day"="Количество дней\nс осадками в месяце, дни"))) +
labs(title = "Зависимость смертности и травматизма от климатических условий", x = "",
y = "Смертность|Травматизм",
caption= "Источники: РОССТАТ, ГИДРОМЕДЦЕНТР")
# Матрица корреляции
select(impact_climate, where(is.numeric),
`Смертн.` = "death_rate", `Травм. ` = "injury_rate",
`℃ ночь ` = "night_temp", `℃ день ` = "day_temp", `Осадки ` = "mean_rain",
`Пасмур.` = "mean_rain_day") %>%
cor() %>%
apply(2,\(x)round(x, 2)) %>%
emphatic::hl_mat(firatheme::scale_color_fira(continuous = TRUE))
# Тест на значимость корреляции между травматизмом и количеством осадков
cor.test(impact_climate$injury_rate, impact_climate$mean_rain, method = "spearman")
# Простая модель линейной регресси для интерпретации
impact_climate %>%
filter(death_rate > 0) %>%
lm(data = ., injury_rate ~ mean_rain) %>%
summary()
Простой способ узнать о новых публикациях – подписаться на Telegram-канал: