
Пресса
Как говорится, не читайте советских западных газет перед обедом… Почему? Потому как после прочтения вам совершенно точно будет страшно и можно заработать несварение. Вот лишь некоторые заголовки на тему атак дронов на НПЗ:
- Bloomberg: Russian diesel exports continue to drop amid Ukrainian drone strikes on oil refineries - The Kyiv Independent
Экспорт дизеля продолжает падать на фоне ударов дронов по НПЗ
- The New York Times: Ukraine Strikes More Russian Oil Facilities in a Bid to Disrupt Military Logistics
Еще больше НПЗ подверглись украинским ударам в попытке разрушения военной логистики
- France24: Ukraine’s drone attacks on Russian oil refineries cause domestic petrol prices to surge - bne IntelliNews
Украинские атаки дронов вызвали скачок внутренних цен на топливо
В общем под впечатлением прочитанного я отправился на ближайшую заправку и залил полный бак 95-го бензина по цене ниже 50 рублей в Питере. В этом конкретном случае была какая-то скидка, но по 55 я бы точно заправился и без скидок. Осознав некоторое несоответствие прочитанного с реальным физическим миром, я решил разобраться и посмотреть объективные данные.
Нефтепродукты
К счастью, в Росстате можно найти данные по реальному производству бензина и дизелного топлива. Учет ведется в недельном разрезе. Как заведено в нашем статистическом ведомстве за несколько лет они умудрились несколько раз изменить схему индикации временного периода. Не удивительно, что в интернете сложно найти толковый график, который хоть как-то бы мог прояснить ситуацию.
К сожалению, даже после приведения в порядок временных меток остались некоторые косяки (за двоения) и наоборот пропуски, которые удалось аккуратно починить. Людям, которые много работают с данными известно, что данные не бывают идеальными, но многим, кто далек от этой области хочется обслуживать свои собственные заблуждения и внутренние установки. Последние могут считать, что Росстат фсе врет и это их личное дело.
Не вижу смысла показывать промежуточные итоги и сразу перейду к финальной версии графика:
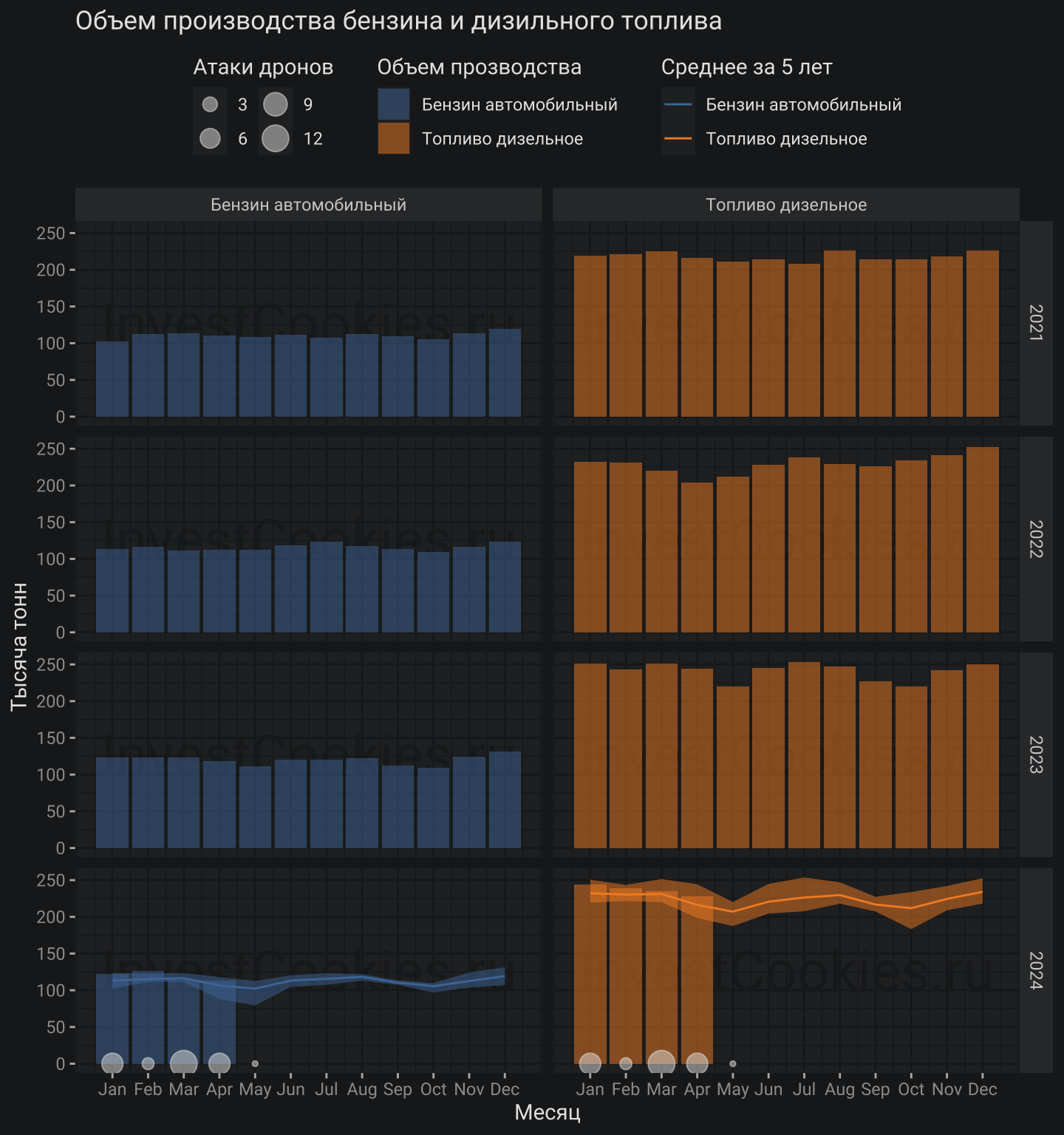
Выводы
- Ничего аномального в производстве бензина и дизельного топлива не выявлено: февраль чуть выше среднего за 5 лет, март где-то в области среднего
- Вероятно, какие-то последствия имеются, но ощутить их будет трудно
- Продолжаю читать западную прессу и искать вдохновений для новых заметок
Исходный код заметки
# Необходимые библиотеки
library(dplyr)
library(stringi)
library(lubridate)
library(ggplot2)
# Загрузка данных с использованием пакета fedstatAPIr
# fedstatAPIr::fedstat_data_load_with_filters("57843") |>
# fst::write_fst("data/prod.fst")
# Загрузка предварительно сохраненных данных
oil_prod <- fst::read_fst("data/prod.fst")
attacks <- readxl::read_excel("data/oil_refine_attacks.xlsx")
# Месяцы в родительном падеже
months_genitive <- c("января", "февраля", "марта", "апреля", "мая", "июня", "июля", "августа", "сентября", "октября", "ноября", "декабря")
# Присвоение порядкового номера к месяцу для дальнейшей обработке
mnth_rcd <- 1:12 |> `names<-`(months_genitive)
# Магия с регулярными выражениями для получения приемлемого формата дат
oil_prod1 <- oil_prod |>
mutate(month0 = stri_extract_all(PERIOD, regex = paste0(months_genitive, collapse = "|"))) |>
mutate(month_start = sapply(month0, \(x)x[1]) |> dplyr::recode(!!!mnth_rcd),
month_finish = sapply(month0, \(x)x[2]) |> dplyr::recode(!!!mnth_rcd)) |>
mutate(month_finish = ifelse(is.na(month_finish), month_start,month_finish)) |>
mutate(week_expr = stri_extract(PERIOD, regex = "\\d{1,2} неделя"),
month_day_start = stri_extract(PERIOD, regex = "(с|С|со|c) \\d{1,2}") |> stri_replace(regex = "(с|С|со|c) ", "") |> as.numeric(),
month_day_finish = stri_extract(PERIOD, regex = "по \\d{1,2}") |> stri_replace(fixed = "по ", "") |> as.numeric()) |>
mutate(week_n = stri_replace(week_expr, fixed = " неделя", "") |> as.numeric()) |>
mutate(year_day_start = week_n*7-7,
year_day_finish = week_n*7-1) |>
mutate(start1 = ymd(paste0(Time, "-01-01")) + year_day_start,
finish1 = ymd(paste0(Time, "-01-01")) + year_day_finish) |>
mutate(start0 = ymd(paste0(Time, "-", month_start, "-", month_day_start)),
finish0 = ymd(paste0(Time, "-", month_finish, "-", month_day_finish))) |>
mutate(start = if_else(is.na(start1), start0, start1),
finish = if_else(is.na(finish1), finish0, finish1)) |>
mutate(finish = if_else(finish>start, finish, finish + 365)) |>
mutate(duration = finish-start) |>
mutate(duration = if_else(duration<0, duration+365, duration)) |>
select(type = s_OKPD2, value = ObsValue, start, finish, duration)
# Распределение значений до дневного уровня гранулярности
oil_prod2 <- purrr::pmap_dfr(oil_prod1, ~{data.frame(type = ..1,
date = ..3 + seq_len(..5+1),
value = ..2/(..5+1))})
# Агрегирование до уровня месяца
oil_prod3 <- oil_prod2 |>
distinct(type, date, .keep_all = TRUE) |> # исключение некоторых дубликатов в статистике РОССТАТА
mutate(year = year(date), day = yday(date), month = month(date)) |>
group_by(type, year, month) |>
summarise(value = mean(value, na.rm = T), .groups = "drop")
# Расчет среднего/максимального/минимального за последние 5 лет
oil_prod_avg <- filter(oil_prod3, year %in% 2019:2023) |>
group_by(type, month) |>
summarise(max = max(value), min = min(value), value = mean(value), .groups = "drop") |>
mutate(year = 2024)
# Агрегирование количества атак по месяцам
attacks1 <- filter(attacks, attack== 1) |>
mutate(month = month(date)) |>
group_by(month) |>
summarise(attack = sum(attack)) |>
mutate(year = 2024)
# График
oil_prod3 |>
filter(year %in% 2021:2024) |>
ggplot(aes(x = month, y = value)) +
geom_col(aes(fill = type), alpha = .5, position = "dodge") +
geom_line(data = oil_prod_avg, aes(col = type)) +
geom_ribbon(data = oil_prod_avg, aes(ymin = min, ymax=max, fill = type), alpha = .5, show.legend = F) +
geom_point(data = attacks1, aes(y = 0, size = attack), alpha = .5) +
facet_grid(year~type) +
scale_x_continuous(labels = month.abb, breaks = 1:12) +
labs(col = "Среднее за 5 лет", fill = "Объем прозводства", size = "Атаки дронов", x = "Месяц", y = "Тысяча тонн",
title = "Объем производства бензина и дизильного топлива") +
guides(fill = guide_legend(nrow = 2, direction = "vertical"), col = guide_legend(nrow = 2, direction = "vertical"),
size = guide_legend(nrow = 2, direction = "vertical"))+
theme(legend.position = "top")
Простой способ узнать о новых публикациях – подписаться на Telegram-канал: