
Немного мотивации
В прошлой заметке я коснулся принципа работы некоторых популярных алгоритмов неточного решения задачи коммивояжера (TSP). Материал получился объемным и сунуть туда еще одно описание алгоритма было бы чрезмерностью. Тем не менее, считаю важным рассказать еще об одном решении, которое носит название - Алгоритм Кристофидеса-Сердюкова. Причины, по которым мне хочется об этом поговорить следующие:
- Речь идет про алгоритм, который часто используется в качестве бенчмарка при оценке эффективности поиска решений сетками с использованием трансформеров, например в работе TranSPormer: A Transformer Network for the Travelling Salesman Problem и не только
- Несмотря на то, что алгоритм назван в честь русского математика в русскоязычном сегменте интернета не так много публикаций на эту тему, можно отметить статью Сердюкова от 1978 и упоминание в Википедии
- Наконец, алгоритм просто красив. Понимаю, что математическая эстетика – это нечто скрытое в глубине вещей и недоступное суетливому взору, но верю, что и такая категория красоты найдет своего читателя.
Важно отметить, что алгоритм гарантирует решение не хуже 3/2 от оптимального и данное неравенство строго доказано аналитически. Безусловно, 3/2 от оптимального решения – звучит не очень перспективно, но в действительности алгоритм работает весьма неплохо, что я и намерен показать ниже в рамках этапа тестирования.
Алгоритм Кристофидеса-Сердюкова строит свое решение на базе теории графов, поэтому нам понадобится какой-то производительный калькулятор операций над графами и для R существует хороший вариант в виде пакета igraph, который написан на языке С. igraph имеет также пакеты-обертки к другим популярным языкам, в том числе к Python. Кроме того, потребуется какой-то солвер для решения локальной оптимизационной задачи с “тонкой” и следовательно шустрой оберткой для R и бекендом на С. В итоге можно собрать достаточно серьезный набор инструментов, необходимый для того, чтобы бросить вызов царь-алгоритму – Concorde.
Когда инструментарий определен, можно вспомнить базовый пример задачи на 16 городов, который был в прошлой заметке и который останется в этой до самого ее завершения:
library(igraph) # пакет для работы с графами
library(tidyverse) # набор инструментов для работы с данными и визуализации
library(lpSolve) # пакет линейной и целочисленной оптимизации
# Загрузка вспомогательных функций из проекта ai_optimization, расположенного на github
"https://raw.githubusercontent.com/dkibalnikov/ai_optimization/refs/heads/main/algorithms/functions.R"|>
source()
# Размерность задачи коммивояжера
n_cities <- 16
# Создание тестовой задачи идентичной задачи из первой заметки
cities <- generate_task()
# Датафрейм базового примера
cities_df <- as.data.frame(cities) |>
transform(n=seq_len(n_cities))
# Матрица расстояний базового примера
dist_mtrx <- as.matrix(dist(cities))
# Построение полного неориентированного графа
G <- graph_from_adjacency_matrix(dist_mtrx, mode='undirected', weighted = TRUE)
# Базовый график визуализации примера
p0 <- ggplot(cities_df, aes(x, y)) +
geom_point() +
geom_point(data = data.frame(n=1, x=0, y=0), shape = 21, size = 5, col = "firebrick") +
geom_text(aes(label = n), nudge_x = 3, nudge_y = 3)
# Датафрейм полного неориентированного графа
full_df <- igraph::as_data_frame(G) |>
mutate(across(1:2, as.integer)) |>
left_join(cities_df, by=c("from"="n")) |>
left_join(cities_df, by=c("to"="n"), suffix = c("_from", "_to"))
# Визуализация
p0 +
geom_segment(data=full_df, aes(x = x_from, y = y_from, xend = x_to, yend = y_to), alpha =.1) +
labs(title = "Полный неориентированный граф для базового примера")

Как видно из кода выше, базовый пример был преобразован в полный неориентированный граф, который можно назвать нулевым этапом алгоритма Кристофидеса-Сердюкова. Каждая вершина такого графа связана с другими вершинами посредством ребер без заданного направления (ориентации).
1. Минимальное остовное дерево
На первом этапе необходимо вычислить Минимальное остовное дерево (Minimum Spanning Tree), то есть связать все вершины графа таким образом, чтобы получилось совокупное минимальное расстояние. Простой пример задачи получения такого дерева – это необходимость строительства дорог между городами, где каждый город должен быть связан с другим напрямую или опосредованно через другой город, и конечно же присутствует желание это сделать минимальной длиной дорожного полотна. Минимальное остовное дерево для базового примера выглядит следующим образом:
# Минимальное остовное дерево
MST <- mst(G) # Алгоритм выбирается автоматически
# Определение вершин графа с нечетной степенью соединений
odd_vertices <- V(MST)[degree(MST) %% 2 == 1] |> as.integer()
# Количество вершин с нечетной степенью
n <- length(odd_vertices)
# Обработка данных для визуализации
MST_df <- igraph::as_data_frame(MST) |>
mutate(across(1:2, as.integer)) |>
left_join(cities_df, by=c("from"="n")) |>
left_join(cities_df, by=c("to"="n"), suffix = c("_from", "_to"))
# Непосредственно визуализация
p0 +
geom_segment(data=full_df, aes(x = x_from, y = y_from, xend = x_to, yend = y_to), alpha =.05) +
geom_segment(data=MST_df, alpha =.6,
aes(x = x_from, y = y_from, xend = x_to, yend = y_to, color="Остовое дерево")) +
geom_point(data = cities[odd_vertices,], aes(col="Нечетные вершины"), size = 5, alpha = .5) +
scale_color_manual(values = c("Нечетные вершины"="firebrick", "Остовое дерево"="white"))+
labs(title = "Минимальное остовое дерево и вершины с нечетной степенью", col="") +
theme(legend.position = "bottom")
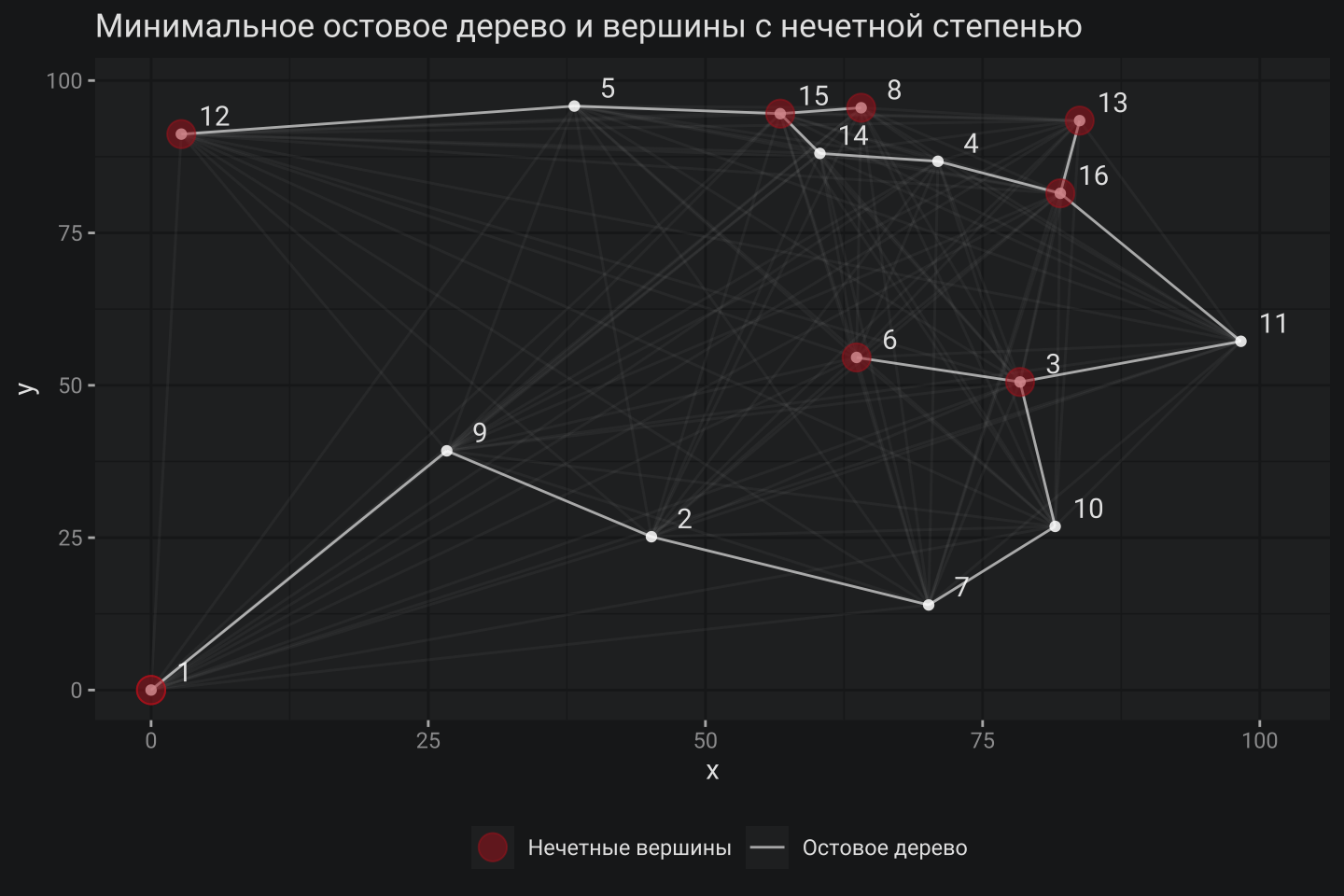
Существует несколько алгоритмов построения Минимального остового дерева, в данном случае igraph делает выбор автоматически, но важно скорее другое, а именно – способность этих алгоритмов находить такое дерево вычислительно очень недорого.
2. Выявление вершин с нечетной степенью
На графике выше кирпичным цветом сразу обозначены вершины графа с нечетной степенью. Если посчитать количество таких нечетных вершин, то выяснится, что такое количество – четно и это не просто совпадение. Существует строгая Лемма о рукопожатиях, согласно которой любой конечный неориентированный граф имеет четное число вершин нечетных степеней. Это закономерность чрезвычайно важна так как позволяет гарантированно связать все без остатка вершины с нечетной степенью между собой.
3. Поиск лучшего сочетания нечетных пар
В оригинальной формулировке этот этап алгоритма звучит как: “Построение совершенного паросочетания минимального веса M в подграфе” (Minimum Weight Perfect Matching). Уверен, что данная формулировка – это есть строгая математическая необходимость, но такой вариант, к сожалению, мало проясняет что же в итоге должно происходить. На самом деле, идея достаточно простая – нужно связать нечетные вершины таким образом, чтобы совокупное расстояние таких связей было минимальным. Именно для этой подзадачи и будет нужен пакет lpSolve. Формальная постановка задачи выглядит следующим образом:
- Целевая функция: [\sum_{i,j}d_{ij}x_{ij} \rightarrow min], где [d] – это длина ребра и [x] – это булева переменная, которая принимает значение 1 в случае наличия связи между вершинами [i] и [j], значение 0 используется для противоположного случая;
- Ограничение на связи вершин: [\sum_{j}x_{ij} =1] – может существовать только одна связь между вершинами;
- Ограничение на симметрию: [x_{ij}=x_{ji}] – означает, что связь в одном направлении равнозначна связи двух вершин в другом.
Некоторую сложность этому этапу добавляет необходимость формирования матрицы ограничений для оптимизатора. Как вариант, можно написать двойной вложенный цикл, но такие способы меня всегда повергали в уныние. В R не принято использовать циклы там где можно использовать математические знания и готовые функции. Действительно, в данном случае можно получить все необходимые комбинации пар с помощью функции combn() и далее пройтись однократным циклом по шаблону матрицы ограничений, что делает код понятным и компактным.
# Матрица расстояний для нечетных вершин
odd_dist_mtrx <- cities[odd_vertices, ] |> dist() |> as.matrix()
# Переход от многомерного матричного представления к плоскому
cost_vector <- odd_dist_mtrx[lower.tri(odd_dist_mtrx)]
# Формирование шаблона матрицы ограничений
constraint_matrix <- matrix(0, nrow = n, ncol = length(cost_vector))
# Подготовка всех возможных сочетаний нечетных вершин
combinations <- combn(n, 2)
# Заполнение шаблона матрицы ограничений
for (col in 1:ncol(combinations)) {
constraint_matrix[combinations[1, col], col] <- 1
constraint_matrix[combinations[2, col], col] <- 1
}
# Решение задачи целочисленной оптимизации
solution <- lp(direction = "min",
objective.in = cost_vector, # коэффициенты целевой функции (длинны ребер)
const.mat = constraint_matrix, # матрица ограничений
const.dir = rep("=", n), # тип ограничения
const.rhs = rep(1, n), # каждая вершина должна попасть в решение один раз
binary.vec = 1:length(cost_vector))
# cat("Итоговое решение: ", solution$objval, "\n")
# Результат оптимизации: сочетание пар вершин
matched_pairs <- combinations[1:2, which(solution$solution == 1)]
# Подготовка данных для визуализации
matched_pairs_df <- data.frame(from=odd_vertices[matched_pairs[1,]], to=odd_vertices[matched_pairs[2,]])
MPM_df <- igraph::as_data_frame(MST) |>
mutate(across(1:2, as.integer)) |>
bind_rows(matched_pairs_df) |>
left_join(cities_df, by=c("from"="n")) |>
left_join(cities_df, by=c("to"="n"), suffix = c("_from", "_to")) |>
mutate(wired = if_else(is.na(weight), "Сочетание нечетных пар", "Остовое дерево"))
# Визуализация
p0 +
geom_segment(data=full_df, aes(x = x_from, y = y_from, xend = x_to, yend = y_to), alpha =.05) +
geom_segment(data=MPM_df, alpha =.6,
aes(x = x_from, y = y_from, xend = x_to, yend = y_to, col = wired, lty=wired)) +
geom_point(data = cities[odd_vertices,], col="firebrick", size = 5, alpha = .5) +
scale_color_manual(values = c(`Сочетание нечетных пар`="firebrick", `Остовое дерево`= "white")) +
scale_linetype_manual(values = c(`Сочетание нечетных пар`=5, `Остовое дерево`= 1)) +
labs(title = "Лучшее сочетания пар с нечетной степенью", col="", lty="") +
theme(legend.position = "bottom")
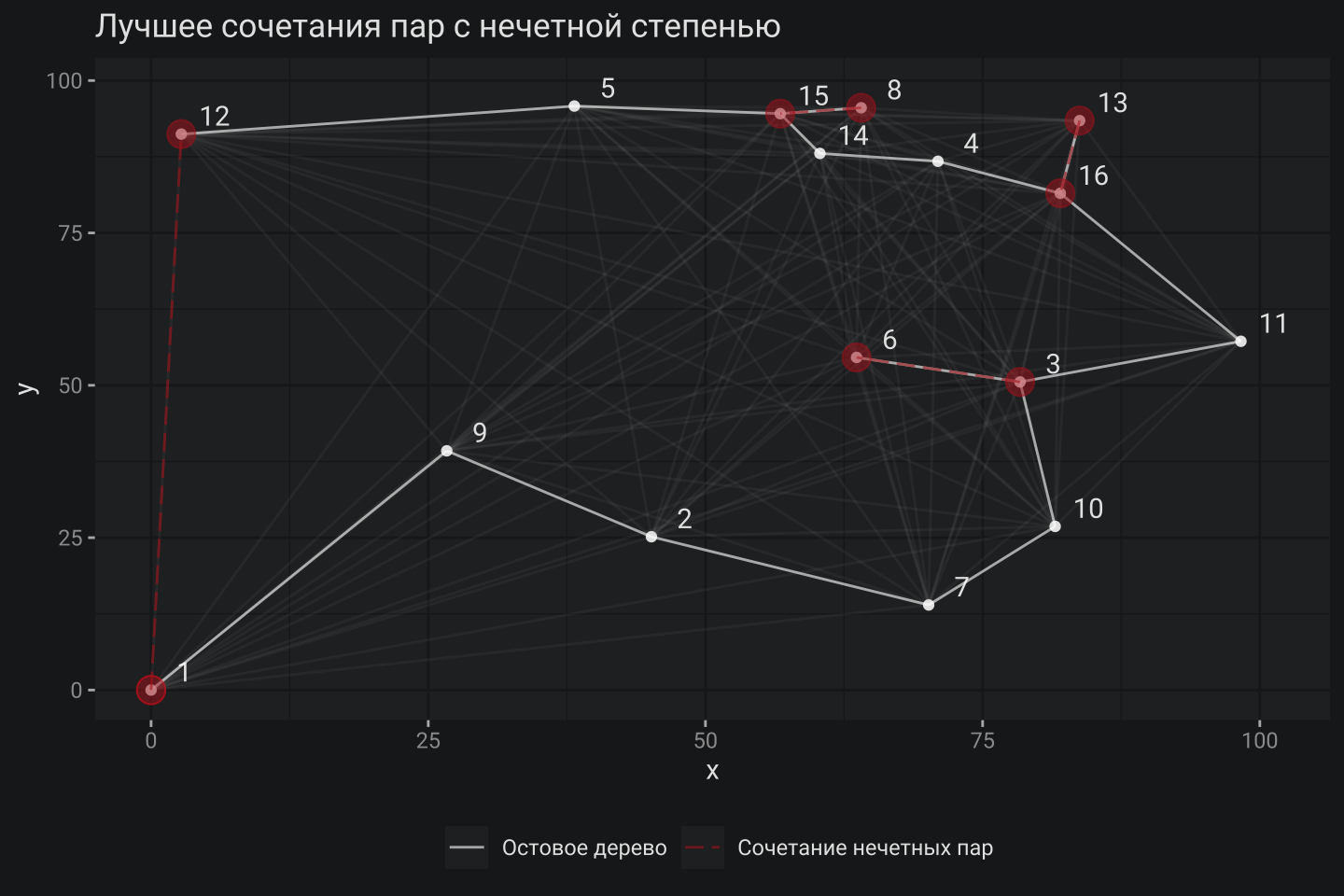
Полученное решение имеет следующее сочетание вершин: 1–12, 6–3, 15–8, при этом два последних сочетания повторяют уже найденные ребра в рамках этапа поиска Минимального остовного дерева. Честно говоря, я пытался избавиться от такого эффекта, усложняя ограничения, но в конечном итоге после более внимательного прочтения имеющихся описаний алгоритма понял, что нет особой нужды бороться с такими случаями. Более того, если убрать такие повторения, то следующий этап – построение Эйлерова графа будет неосуществим.
Если посмотреть примеры реализации алгоритма на Python, то там используется другой подход, то есть не поиск решения в контексте MIP, а иной итерационный метод. Это решение можно посмотреть в исходном коде пакета NetworkX. Не берусь судить, какой метод лучше, но отмечу важность этого этапа, так как именно он определяет вычислительную сложность алгоритма [O(n^3)].
4. Построение Эйлерового цикла
Эйлеровым циклом или путем называют такой обход графа, при котором каждое ребро задействовано лишь один и только один раз. Единственное, что нужно сделать перед тем как использовать готовую функцию igraph::eulerian_path() – это добавить ребра от лучшего сочетания нечетных пар к Минимальному остовному дереву:
EP <- add_edges(MST, odd_vertices[as.vector(matched_pairs)]) |> # добавление ребер
eulerian_path() # Построение Эйлерового цикла
5. Устранения повторяющихся вершин
Это завершающий этап превращения Эйлерова цикла в Гамильтонов, необходимым условием которого, является прохождение пути через вершину один и только один раз. Действительно, в базовом примере по вершинам 6–3, 15–8 проход осуществляется дважды: туда и обратно. Это следует исправить. Способ исправления достаточно прямолинейный: при обнаружение повторения вершины осуществляется простой переход к следующей. Благодаря неравенству треугольника сокращение вершины не увеличивает длину совокупного маршрута, но гарантированно сокращает.
# Функция удаления лишних вершин
shortcut_path <- function(EP){
HP <- c()
for(vertex in EP){
if (!vertex %in% HP | vertex == EP[1L]){ # первая вершина исключается
HP <- c(HP, vertex)
}
}
return(HP)
}
# Переход от Эйлерова к Гамильтонову циклу
HP <- shortcut_path(names(EP$vpath)|> as.integer())
# Визуализация итогового решения
p0 +
geom_segment(data=full_df, aes(x = x_from, y = y_from, xend = x_to, yend = y_to), alpha =.05) +
geom_segment(data=MPM_df, col="white", linewidth = 1.5, alpha=.3,
aes(x = x_from, y = y_from, xend = x_to, yend = y_to, lty="Эйлеров цикл")) +
geom_point(data = cities[odd_vertices,], col="firebrick", size = 5, alpha = .5) +
geom_path(data = cities_df[HP,], aes(col=seq_along(HP), lty="Гамильтонов цикл")) +
scale_color_viridis_c(begin = .3) +
scale_linetype_manual(values = c(`Эйлеров цикл`=5, `Гамильтонов цикл`=1)) +
labs(col="Очередность", linetype="",
title = paste0("Итоговое решение: ", calc_dist4mtrx(dist_mtrx, HP)|>round(2))) +
theme(legend.position = "bottom")
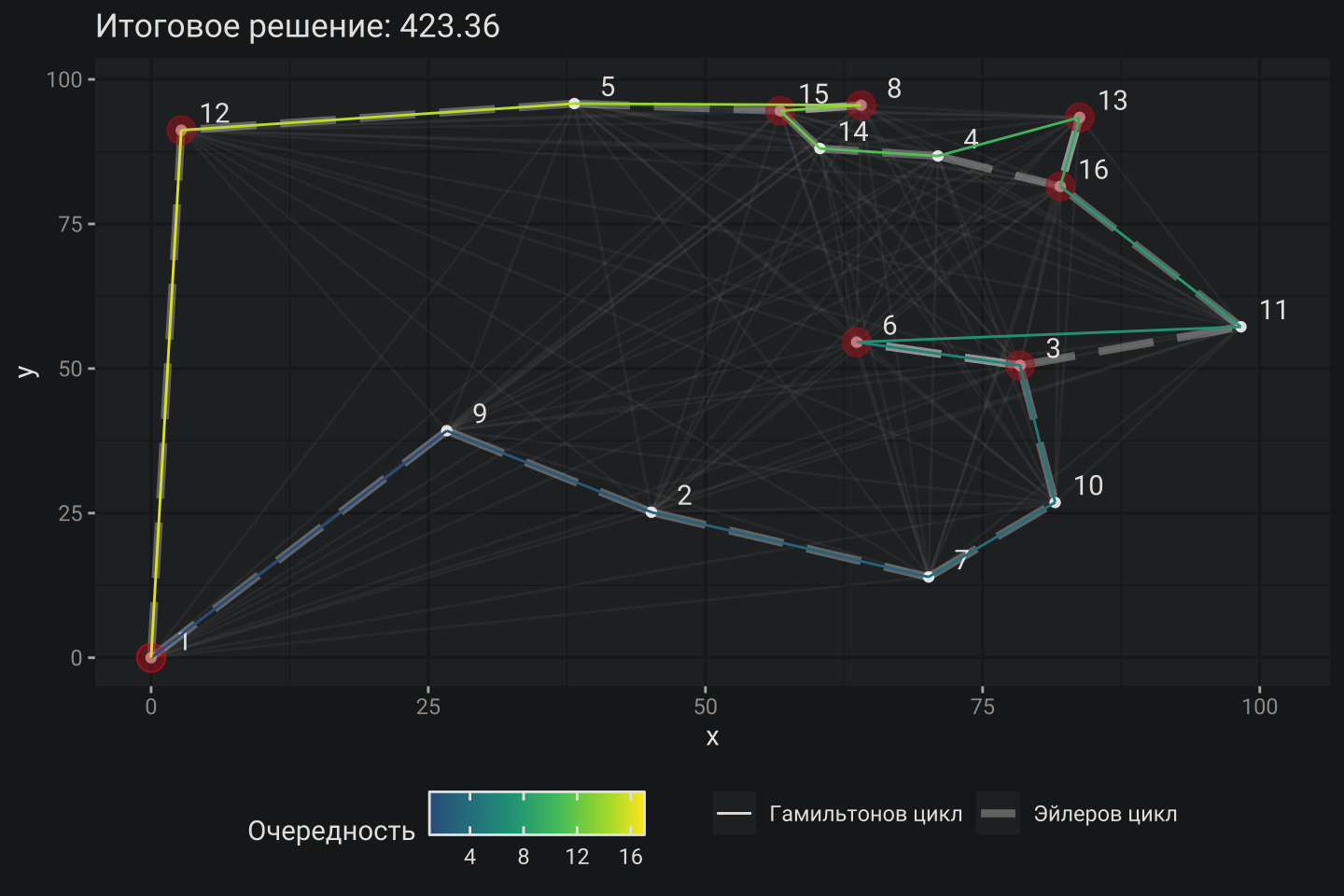
Вот, собственно, и все, что касается принципов работы алгоритма.
Тестирование
Теперь любопытно посмотреть, как алгоритм Кристофидеса-Сердюкова смотрится на фоне ранее представленных аналогов. Все подробности тестовых расчетов, исходный код и результаты расчетов, как и прежде, можно найти на github. Звезды в карму проекта – категорически приветствуются!
Точность решения
 Несмотря на пугающий коэффициент 3/2 аппроксимации Кристофидеса-Сердюкова, на практике все выглядит совсем неплохо. Алгоритм уверенно переигрывает всех, кроме Concorde и 2-opt на большой размерности (64 города).
Несмотря на пугающий коэффициент 3/2 аппроксимации Кристофидеса-Сердюкова, на практике все выглядит совсем неплохо. Алгоритм уверенно переигрывает всех, кроме Concorde и 2-opt на большой размерности (64 города).
Скорость вычислений
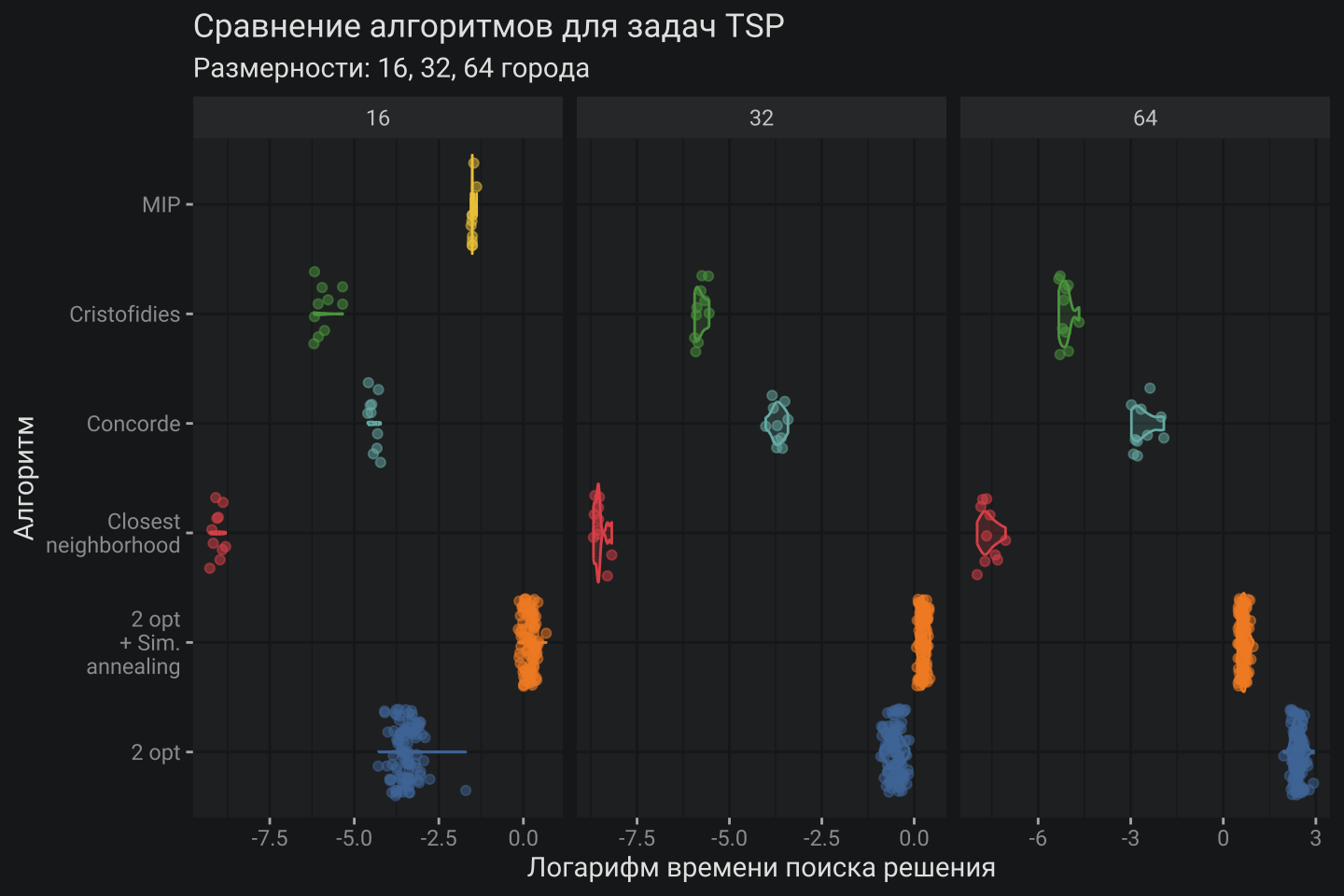 В этой номинации алгоритм Кристофидеса-Сердюкова занимает уверенное второе место вслед за эвристикой ближайшего города и это по-моему прекрасный результат.
В этой номинации алгоритм Кристофидеса-Сердюкова занимает уверенное второе место вслед за эвристикой ближайшего города и это по-моему прекрасный результат.
В итоге получился очень шустрый алгоритм, способный находить приемлемые решения задачи коммивояжера и готовый для повседневного использования. Если алгоритм немного доработать для задачи с множеством коммивояжеров и добавить асимметричные ограничения на обход ребер, то таким уже боевым инструментом возможно планировать маршруты, скажем, для флота газелей по развозке чего-нибудь гастрономического по торговым точкам города.
Спасибо всем, кто нашел силы дочитать заметку до конца.
Некоторые полезные источники на тему
- The Chistofides Algorithm - Alon Krymgand
- igraph
- NetworkX Christofides
- Проект AI optimization на Github
- Специалисты по информатике идут нехожеными дорогами
Простой способ узнать о новых публикациях – подписаться на Telegram-канал: