
Продолжаю серию заметок про рецессию в США и методы ее раннего обнаружения. Предыдущие заметки серии:
- Рецессия пришла, но это не точно
- Так есть ли рецессия? 🔻🔻🔻
- Марковская модель с переключением 🕹⛓🕹
- Рецессия и DataScience 💪🧠
Полагаю, мое небольшое исследование примет более завершенный вид, если будет разработан прогноз наступления рецессии в США на горизонте ближайших 12 месяцев. Напомню, что в предыдущих заметках задача сводилось к оценке наличия рецессии в текущий момент времени в условиях запоздалой официальной статистики. Мало того, что результат прогнозирования имеет сугубо прикладной смысл, позволяя принимать инвестиционные решения, но и сам процесс разработки модели прогнозирования значим с точки зрения улучшения понимания сути происходящих явлений. В качестве сигналов грядущей рецессии я буду использовать хорошо известные финансовым рынкам опережающие индикаторы.
Исходный код, как обычно, доступен для проверки и самостоятельного изучения. Первый кусок кода по традиции связан с загрузкой пакетов и подготовкой всяких полезностей:
library(data.table) # быстрый пакет для работы с табличными данными
library(collapse) # быстрый пакет для работы с табличными данными
library(stringi) # пакет для работы с текстовой информацией
library(DT) # пакет создания интерактивных таблиц
library(echarts4r) # интерактивные графики
library(firatheme) # палитра, которую я использую для непрерывных индикаторов
library(emphatic) # пакет для раскрашивания матриц и табличек для наглядности
library(lightgbm) # пакет с алгоритмом LightGBM
library(DALEX) # пакет диагностики моделей машинного обучения
library(ggpp) # расширение для ggplot2
library(thematic) # пакет для автоматической установки стилей графиков
# Палитра
my_pal <- palette.colors(palette = "Tableau") %>% unname()
# Тема для блога
thematic_rmd(bg = "#1D1E20", accent = "cyan", fg = "grey90",
font = font_spec("Roboto"), sequential = firatheme::firaPalette(100),
qualitative = palette.colors(palette = "Tableau"))
Исходные данные 💿
Я продолжаю пользоваться сведениями, любезно предоставленными ФРС США. В качестве опережающих индикаторов для построения модели были выбраны следующие данные:
UNRATE– уровень безработицыT10Y3M– разница между краткосрочными и долгосрочными ставками заимствования, далее спред ставокDFF– эффективная ставка федеральных фондов, далее эффективная ставка
Каждый из перечисленных индикаторов имеет весьма интересные фундаментальные основания. Аналитики, занимающиеся финансовыми рынками, активно используют эти индикаторы при попытках прогнозировать движения рынков. Впрочем более-менее стройная теория по этому поводу в академическом мире отсутствует или же она мне просто не известна. Прежде всего необходимо взглянуть на динамику этих индикаторов:
# Загрузка подготовленных данных
indctrs0 <- fst::read_fst("data/indctrs.fst", as.data.table = TRUE)
preds <- c("UNRATE", "T10Y3M", "DFF")
indctrs0 |>
tfm(USREC = USREC*15) |>
e_charts(date) |>
e_line(UNRATE, symbol= 'none') |>
e_line(T10Y3M, symbol= 'none') |>
e_line(DFF, symbol = 'none') |>
e_area(USREC, symbol= 'none', lineStyle = list(width = 0),
name = "Период рецессии", color = "rgba(225, 87, 89, .5)") |>
e_tooltip(trigger = "axis", formatter = e_tooltip_pointer_formatter("decimal", 2)) |>
e_datazoom(x_index = 0:2) |>
e_draft("InvestCookies.ru", size = "80px", opacity = 0.2) |>
e_title(text = "Опережающие индикаторы (предикторы модели)") |>
e_x_axis(name = "Месяц") |>
e_legend(padding = 30) |>
e_color(color = my_pal)
Можно заметить, что эффективная ставка имеет отрицательную корреляцию со спредом ставок. Также выделяется запредельная волатильность индикатора безработицы в период пандемии COVID, как наглядная демонстрация того, что человечество впервые столкнулось с такой напастью. Впрочем не менее справедливо будет заметить, что человечество не в первый, но в очередной раз осознало свою уязвимость перед сюрпризами природы.
Кроме непосредственных значений опережающих индикаторов был также проведен незамысловатый feature engineering, подобный тому, который я приводил в своих предыдущих заметках:
- суффикс
dnхарактеризует абсолютные изменения предикторов - суффикс
sd3характеризует стандартное отклонение для абсолютных изменений предикторов за три последних месяца - суффикс
mn3характеризует среднее для абсолютных изменений предикторов за три последних месяца - суффикс
sd6характеризует стандартное отклонение для абсолютных изменений предикторов за шесть последних месяца - суффикс
mn6характеризует среднее для абсолютных изменений предикторов за шесть последних месяца
mdl_dt <- indctrs0 %>%
# Получение сдвига на один период
.[, (stri_c(preds, "_dn")) := lapply(.SD, \(x) x - shift(x)), .SDcols = preds] %>%
.[, (stri_c(preds, "_sd3")) := lapply(.SD, \(x)frollapply(x, n=3, fsd)), .SDcols = preds] %>%
.[, (stri_c(preds, "_mn3")) := lapply(.SD, \(x)frollapply(x, n=3, fmean)), .SDcols = preds] %>%
.[, (stri_c(preds, "_sd6")) := lapply(.SD, \(x)frollapply(x, n=6, fsd)), .SDcols = preds] %>%
.[, (stri_c(preds, "_mn6")) := lapply(.SD, \(x)frollapply(x, n=6, fmean)), .SDcols = preds] %>%
.[, (stri_c(preds, "_sd3_dn")) := lapply(.SD, \(x)frollapply(x, n=3, fsd)), .SDcols = (stri_c(preds, "_dn"))] %>%
.[, (stri_c(preds, "_mn3_dn")) := lapply(.SD, \(x)frollapply(x, n=3, fmean)), .SDcols = (stri_c(preds, "_dn"))] %>%
.[, (stri_c(preds, "_sd6_dn")) := lapply(.SD, \(x)frollapply(x, n=6, fsd)), .SDcols = (stri_c(preds, "_dn"))] %>%
.[, (stri_c(preds, "_mn6_dn")) := lapply(.SD, \(x)frollapply(x, n=6, fmean)), .SDcols = (stri_c(preds, "_dn"))] %>%
tfm(USREC_pred = shift(USREC, n = -12, fill = NA)) |>
fsubset(date > as.Date("1982-01-01"))
rec_dt <- na_omit(mdl_dt)
datatable(rec_dt[1:30], style = 'bootstrap4', extensions = 'Responsive',
options = list(pageLength = 6), caption = "Предикторы рецессии") %>%
formatRound(columns = 3:24)
Моделирование 🥸
Для моделирования будет использован алгоритм LightGBM, уже известный по предыдущей заметке. Можно также сказать что использовались базовые настройки, которых вполне достаточно для получения сносного результата. Пусть будет получен не идеальный результат, но этого будет достаточно для демонстрации подхода и формирования представлений по поводу эффективности опережающих индикаторов.
Данные были разбиты на обучающую/тестовую выборки в соотношении 80%/20%. Промежуточным результатом будет выведена диаграмма значимости предикторов.
n_rows <- fnrow(rec_dt) # количество наблюдений
indx_split <- round(n_rows*0.80) # индекс для определения обучающей выборки
split_date <- rec_dt$date[indx_split]
# Обучающая выборка данных
dtrain <- lgb.Dataset(as.matrix(rec_dt[1:indx_split, -c("date", "USREC_pred")]), label = rec_dt$USREC_pred[1:indx_split])
# Выборка данных для тестирования
dtest <- lgb.Dataset(as.matrix(rec_dt[(indx_split + 1):n_rows, -c("date", "USREC_pred")]), label = rec_dt$USREC_pred[(indx_split + 1):n_rows])
# Параметры модели
params <- list(objective = "binary", metric = "binary_error", learning_rate = .75)
# Моделирование
rec_lgb <- lgb.train(params = params, data = dtrain, nrounds = 100L, verbose = -1,
valids = list(test = dtest), early_stopping_rounds = 30L)
lgb.importance(rec_lgb , percentage = TRUE)[order(Gain)] |>
e_chart(Feature) |>
e_bar(Gain) |>
e_bar(Cover) |>
e_bar(Frequency) |>
e_draft("InvestCookies.ru", size = "60px", opacity = 0.2) |>
e_title(text = "Важность предикторов (фич) для предсказания модели") |>
e_y_axis(name = "Процент", formatter = e_axis_formatter("percent")) |>
e_x_axis(name = "Предиктор", axisLabel = list(margin = -5.7e2)) |>
e_legend(padding = 30) |>
e_tooltip(formatter = htmlwidgets::JS("function(params){
return `${params.value[1]}<br/>
<strong>${(params.value[0]*100).toFixed(2)}%</strong>`}")) |>
e_flip_coords() |>
e_color(color = my_pal)
В прошлой заметке уже давались пояснения относительно показателей, характеризующих значимость предикторов.
Данная модель демонстрирует хорошую прогнозирующую способность ~40% для предиктора T10Y3M_mn6, который является не чем иным как скользящее среднее за шесть месяцев спреда ставок. T10Y3M_sd6_dn имеет также существенную значимость в размере ~15% и в целом характеризует волатильность спреда ставок скользящим стандартным отклонением за шесть месяцев. Лишь на третьем месте со значением ~12% находится UNRATE_mn6т.е. скользящие среднее за шесть месяцев индикатора безработицы.
Любопытно, что эффективная ставка DFF, а также ее производные от него, не являются особо значимыми для прогнозирования рецессии на грядущие 12 месяцев. Это особенно важно сегодня когда ставка поднялась с нулевых значений к уровню более 3% чего не наблюдалось с далекого 2008 года. Последние пол года можно наблюдать как финансовые рынки попали в настоящию резню после многих лет безмятежного роста, поддерживаемого снижением эффективной ставки и программами количественного смягчения. Тем не менее, похоже, что для реальной экономики текущее резкое повышение эффективной ставки не будет критичным.
Прогнозирование 🔮
На тестовом наборе данных модель демонстрирует следующую точность:
# Функция которая считает полезные метрики модели
get_metrics <- function(dt){
mtrx <- tfmv(dt, vars = 1:2, FUN = \(x)factor(x, levels = 0:1)) |> table()
n <- fnrow(dt)
accuracy <- round(fsum(diag(mtrx))/n, 2)
precision = round(diag(mtrx) / colSums(mtrx) , 2)
recall = round(diag(mtrx) / rowSums(mtrx), 2)
f1 = round(2 * precision * recall / (precision + recall) , 2)
qDF(mtrx) |> cbind(data.frame(metrics = c("->", "->"), precision, recall, f1)) |>
hl(scale_color_fira(continuous = TRUE), cols = 1:2, calc_scale = "each") |>
as_html(style = "color:White")
}
rec_dt[date > split_date] |>
tfm(mdl = predict(rec_lgb, as.matrix(rec_dt[date > split_date, -c("date", "USREC_pred")]))) %>%
tfm(pred = fifelse(mdl > .5, 1, 0)) |>
fselect(USREC_pred, pred) |>
get_metrics()
0 1 metrics precision recall f1 0 91 1 -> 0.98 0.99 0.98 1 2 0 -> 0.00 0.00 NA
Модель дважды не смогла правильно определить наличие рецессии и также один раз ошибочно указала на рецессию, когда в реальности ее не было. Казалось бы основная функция модели в виде предсказания рецессии выполняется не очень хорошо, но так ли все плохо на самом деле? Более полную картину можно увидеть при просмотре временного ряда прогноза вероятности рецеcсии с захватом прогнозного периода на 2023 год:
data.table(date = seq(fmin(mdl_dt$date[13:fnrow(rec_dt)]), length = fnrow(mdl_dt), by = "month"),
mdl = predict(rec_lgb, as.matrix(mdl_dt[, -c("date", "USREC_pred")]))) %>%
merge(mdl_dt, by = "date", all = TRUE) |>
e_charts(date) |>
e_area(USREC, symbol= 'none', lineStyle = list(width = 0),
name = "Период рецессии", color = "rgba(225, 87, 89, .5)") |>
e_line(mdl, symbol= 'none', color = my_pal[1], lineStyle = list(width = 1),
name = "Вероятность рецессии LGB") |>
e_datazoom(x_index = 0, type = "slider") |>
e_title(text = "Оценка вероятности рецесии в США на ближайший год") |>
e_y_axis(name = "Вероятность рецесии", formatter = e_axis_formatter("percent")) |>
e_x_axis(name = "Месяц") |>
e_draft("InvestCookies.ru", size = "60px", opacity = 0.2) |>
e_legend(padding = 30) |>
e_tooltip(trigger = "axis", axisPointer = list(type = "line"),
backgroundColor = "rgba(255,255,255,0.7)",
formatter = e_tooltip_pointer_formatter("percent")) |>
e_mark_area(serie = "Период рецессии", data = list(list(xAxis = as.Date("2022-09-01"), name = "Прогноз"),
list(xAxis = as.Date("2024-07-01"))),
itemStyle = list(color = my_pal[1], opacity = .2)) |>
e_mark_area(serie = "Вероятность рецессии LGB", data = list(list(xAxis = split_date, name = "Тест"),
list(xAxis = as.Date("2022-09-01"))),
itemStyle = list(color = my_pal[2], opacity = .2))
На обучающем периоде данных модель закономерно показывается уверенные и точные скачки вероятности наступления рецессии. Краткосрочная рецессия 2020 года не была прогнозирована корректно, но тем не менее модель указала на несколько сильных скачков вероятности рецессии в непосредственной близости от корректного периода. Думаю, можно сделать некоторую скидку для модели с учетом того, что она пытается определить точный месяц рецессии на горизонте 12 месячного прогнозирования, но в действительности для принятия решений вполне достаточно получить сигнал о резком росте вероятности рецессии с разбросом 2-3 месяца.
Получается, что несмотря на кажущуюся непредсказуемость наступления пандемии – рецессия, вызванная этой пандемией, была вполне прогнозируемой: либо пандемия просто совпала по времени с завершением бизнес-цикла, либо она была удобным инструментом обоснования агрессивной политики количественного смягчения. Во втором случае истина вряд ли когда-либо станет официальной версией поэтому проще исходить из гипотезы того, что имело место быть просто совпадение 😎
Как можно заметить на графике выше, модель прогнозируют начало будущей рецессии в период с мая по ноябрь 2023 с учетом 3-месячного разброса, установленного эмпирическим образом. Как и предполагалось, резкое повышение эффективной ставки не сильно сказывается на сваливание экономики в рецессию: страдают только финансовые рынки и пенсионеры, накопление которых попали под каток жесткой денежно-кредитной политики ФРС США.
Несмотря на то, что LighGBM – является моделью машинного обучения, и следовательно плохо поддается интерпретации, существуют методы диагностики модели по принципу черного ящика для конкретных прогнозных значений. В данном случае интересно будет посмотреть каким образом формируется прогноз на 2020-07-01 т.е. прогноз наступления рецессии из-за пандемии:
model_explanation <- explain(rec_lgb, data = as.matrix(mdl_dt[1:indx_split, -c("date", "USREC_pred")]),
y = mdl_dt$USREC_pred[1:indx_split], verbose = FALSE)
# Функция для декорирования графика
branding <- \(x) x +
annotate("text_npc", npcx = .9, npcy = .2, alpha = .9, size = 8,
label = "InvestCookies.ru", color = "#1D1E20") +
scale_fill_manual(values = my_pal) +
theme_minimal() +
theme(panel.background = element_rect(fill ="gray15"), plot.background = element_rect(fill ="#1D1E20"),
axis.text = element_text(color = "gray80"), panel.grid = element_line(colour = "gray20"),
text = element_text(color = "gray80"))
breakDown::break_down(model_explanation, keep_distributions = TRUE,
new_observation = as.matrix(mdl_dt[date == as.Date("2019-07-01"), -c("date", "USREC_pred")])) |>
plot() %>%
branding
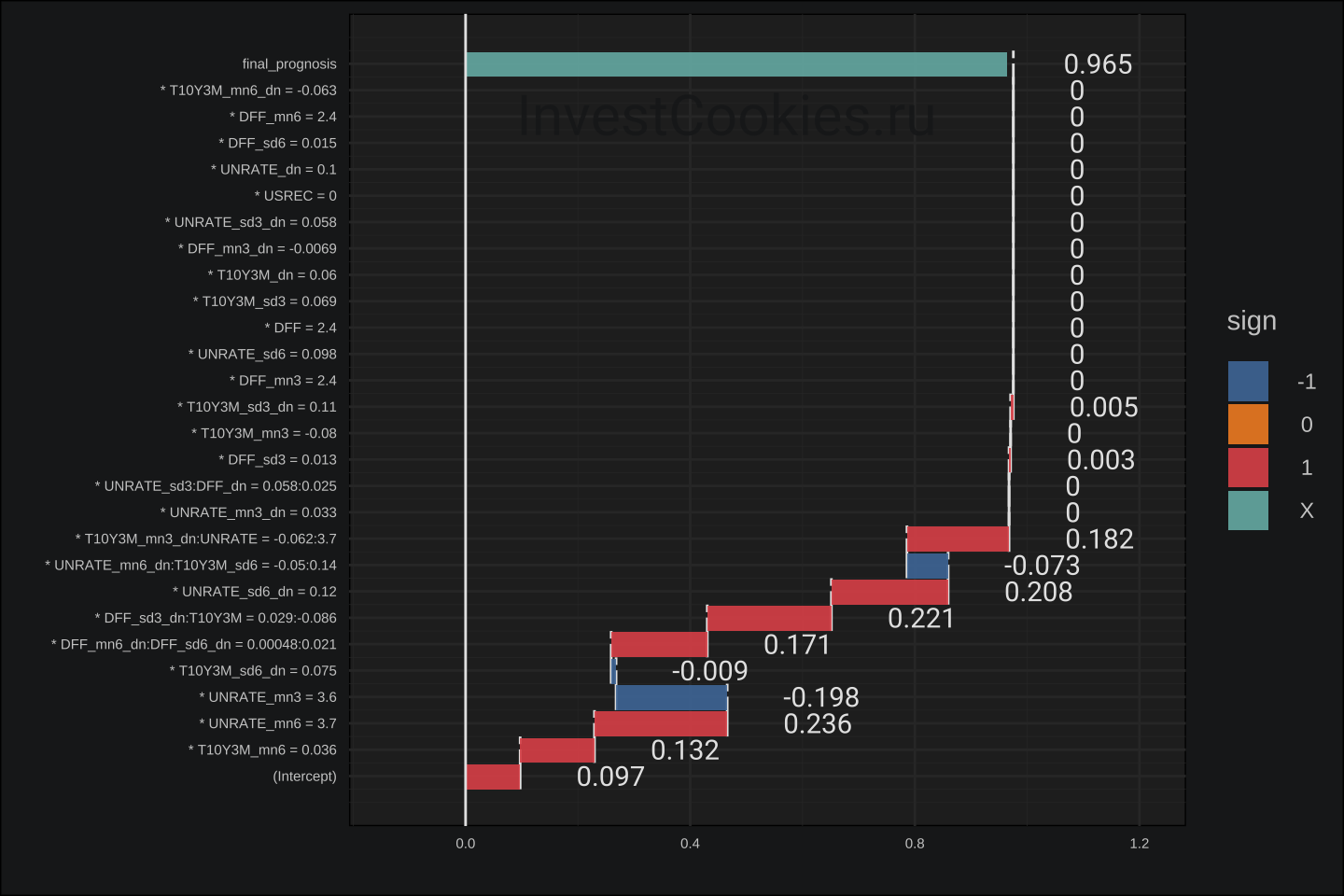
Основными драйверами прогноза – являются предикторы T10Y3M и UNRATE, а также производные на их основе. Аналогичный график для прогноза августа грядущего 2023 года:
breakDown::break_down(model_explanation, keep_distributions = TRUE,
new_observation = as.matrix(mdl_dt[date == as.Date("2022-08-01"), -c("date", "USREC_pred")])) |>
plot() %>%
branding
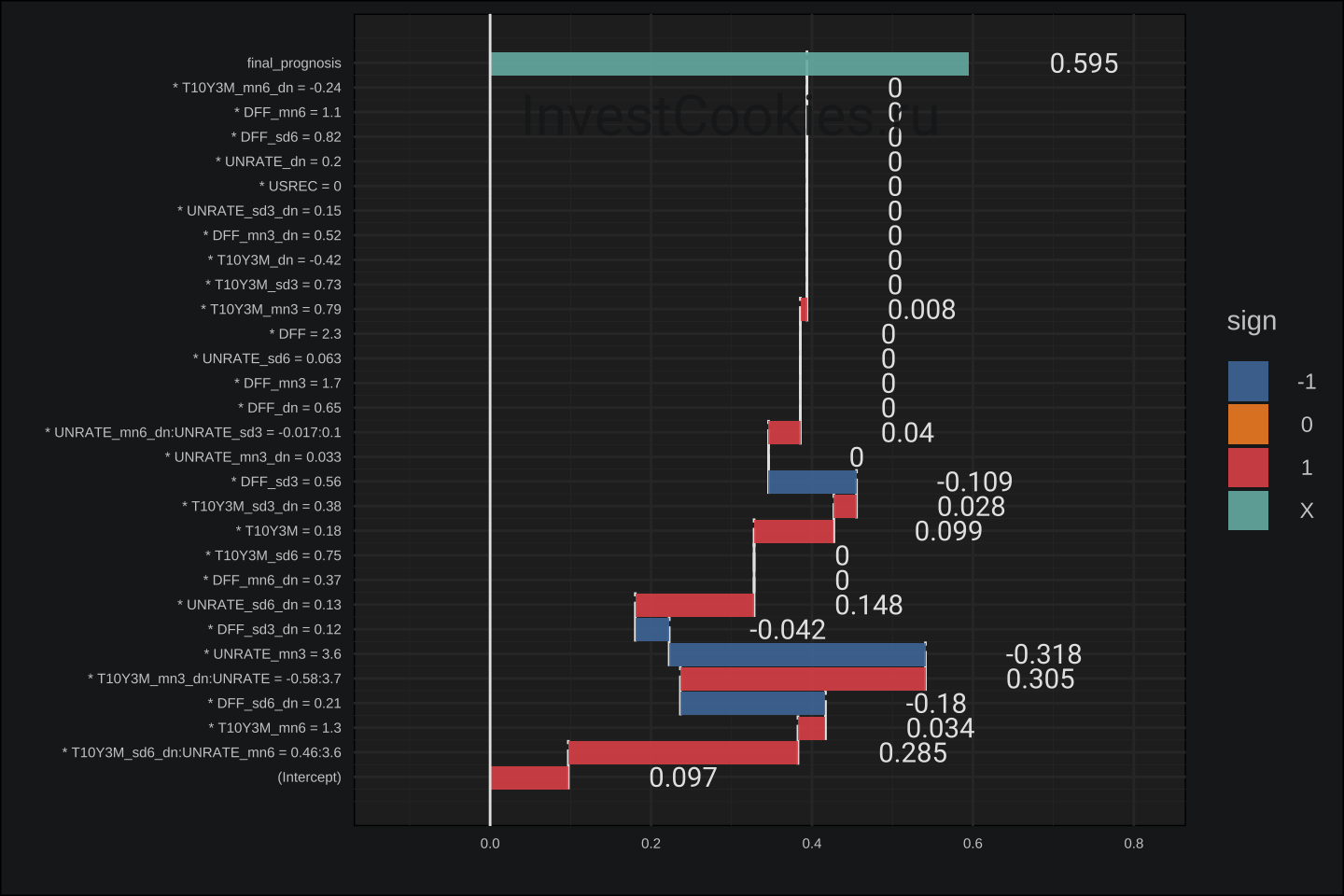
Наибольший вклад в предсказание рецессии вносят предикторы взаимодействия волатильности спреда ставок и усредненных показателей уровня безработицы. Напомню, что спреда ставок имел сильное движение за последние пол года, а безработица некоторое время находится на достаточно низких уровнях.
В глазах обывателя низкая безработица – есть позитив для экономики, а спред ставок вообще похож на какую-то нумерологию: взяли разницу ставок по десятилетним облигациями и трех-месячным, далее на основе этого делают прогнозы. Более того, прогноз дают не сами предикторы, а какое-то магическое сочетания одного с другим после замысловатой математической машинерии. Возникают вопросы: можно ли доверять такому прогнозу? Какой реальный экономический смысл, выявленных моделью закономерностей? На этих вопросах разумно остановиться в рамках данной заметки, уделив пояснению экономического смысла отдельный пост, в котором будет попытка на пальцах пояснить как работают экономические циклы и почему они трудно поддаются прогнозированию.
Выводы 🍪
Заметка получилась достаточно технической, тем не менее можно сделать выводы, любопытные для широкого круга читателей:
- Опережающие индикаторы, которые широко используются аналитиками финансовых рынков действительно могут быть использованы для прогнозирования экономических циклов и рецессии в частности
- Наиболее значимые опережающие индикаторы: 1) уровень безработицы и 2) разница между краткосрочными и долгосрочными ставками доходностей облигаций
- Следующая рецессия в США наступит, вероятно, в период с мая по ноябрь 2023
- Эффективная ставка федеральных фондов имеет ограниченное влияние на динамику экономического цикла, что важно в условии резкого роста этой ставки в последнее время
Простой способ узнать о новых публикациях – подписаться на Telegram-канал: